
DeepSeek+本地知识库:三大主流笔记本方案实战对比
 2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
开源的、中国的DeepSeek,引爆了千行百业,让AI真正走进了千家万户。每个公司,每台电脑,都可以拥有属于自己的忠诚的AI助理。
基于自己的知识库部署一套专有的大模型AI很难吗?其实不难,还很好玩!
下面我就详细介绍目前3大主流方案的本地部署方法,并进行对比,朋友们可以收藏评阅,或者自己亲自操刀玩一玩。
方案一:Deepseek+RAGflow
1. 方案简述:
在个人笔记本电脑上安装部署AI大模型Deepseek,配合模型应用工具RAGflow,建立个人或团队基于私有知识库的AI助手。
2. 技术环境:
本地大模型(LLM):Deepseek,运行环境:windows11,作用是实现AI对话。
模型应用工具:RAGflow,运行环境:windows11上的Docker Desktop,作用是实现本地知识库解析。
笔记本硬件:Thinkbook16+,Intel Ultra9+32G内存+NVIDIA GeForce RTX 4060(8G显存)
3. 安装过程
3.1. 安装ollama
3.1.1. ollama 是一个开源跨平台大模型工具,基于 Go 语言开发,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。可以理解为没有ollama就没办法在本机上运行LLM。
3.1.2 上ollama官网下载ollama:https://ollama.com/download,并安装。
ollama安装文件约1G,安装简单顺畅。 建议统一安装在D:\AI目录,便于使用。后文默认使用此路径。
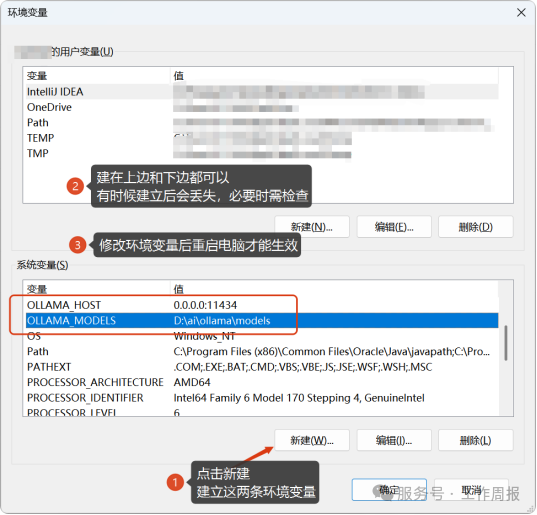
3.1.3 配置ollama环境变量
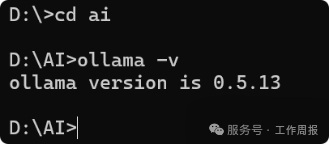
按下“Win+R”快捷键,输入“sysdm.cpl”,点击“高级”页签,点击“环境变量”按钮。 OLLAMA_HOST:0.0.0.0:11434(作用:让RAGFlow能够访问到本机上的Ollama) LLAMA_MODELS: D:\AI\OLLAMA(作用:ollama会把模型下载到这个位置) 设置好环境变量后重启电脑生效。 重启后在CMD窗口中执行ollama验证安装是否正确。
3.2. 下载DeepSeek
3.2.1. 上ollama官网下载ollama:https://ollama.com/search,下载合适的deepseek版本
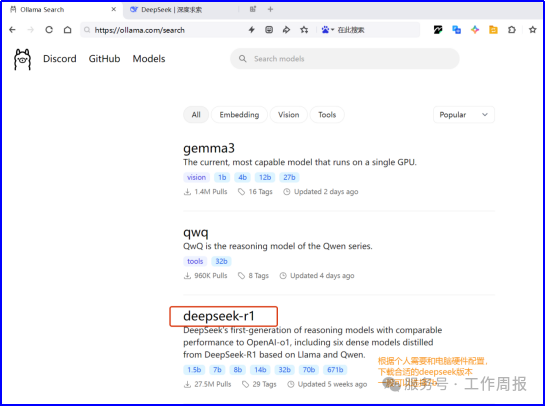
根据个人电脑配置情况下载不同参数量的版本,参数越大要下载的文件越大,AI的智能也越高。 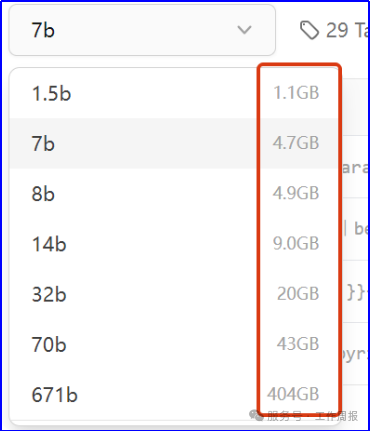
如果下载7b模型,在CMD窗口中执行:ollama run deepseek-r1:7b 特别说明:下载后的deepseek模型文件应该统一存放在D:\AI\ollama\models目录下,如果不留神下载到了其他目录,把模型文件复制到该目录下即可。 下载完成后在CMD窗口中执行“ollama list”命令检查。
3.3. 下载Docker
3.3.1. 上docker官网:https://www.docker.com/,Download for Windows - AMD64
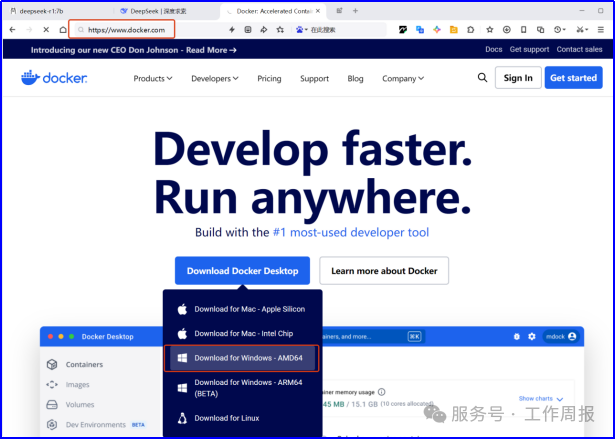
Docker镜像是一个封装好的linux运行环境,包含了所有运行RAGFlow所需的依赖、库和配置,能直接运行RAGFlow。 安装docker时,默认要安装WSL,不安装Docker Desktop无法运行。 特别说明,在windows上运行Docker Desktop,WSL占用资源极大,占用内存10G起步。如果在linux上运行Docker会好非常多,但是没有提供Centos的Docker环境,所以没有操练。 
安装完毕在cmd中执行“docker -v”验证。 
启动Docker Desktop时会提示注册,但实际上可以不注册直接使用。
3.4. 下载RAGflow源代码
3.4.1. 下载RAGflow源代码地址:https://github.com/infiniflow/ragflow,点击code按钮,download zip。
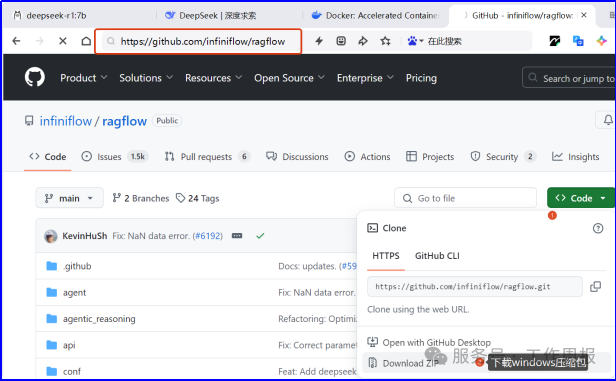
解压到D:\AI\ragflow-main。 然后修改D:\AI\ragflow-main\docker\.env配置文件。修改的目的是下载ragflow Docker的镜像:v0.17.1,而不是RAGFlow slim Docker镜像v0.17.1-slim。Slim版本没有embedding模型。
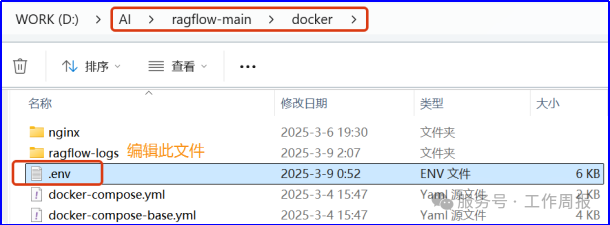
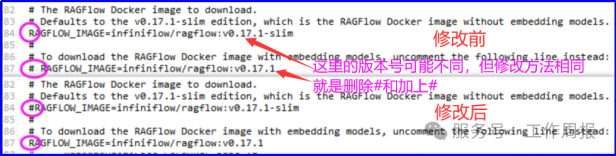
embedding模型是用于向量化本地知识库文件的。
3.5. 下载docker中的RAGflow镜像(运行环境)
3.5.1. 在CMD中进入D:\AI\ragflow-main,执行:
docker compose -f docker/docker-compose.yml up -d这是下载ragflow Docker镜像:v0.17.1。下载成功后会自动启动相关服务。 特别提醒:这个下载过程非常慢。如果没有VPN,可能非常周折,主要是“https://registry-1.docker.io/v2/"这个下载地址可能无法访问。
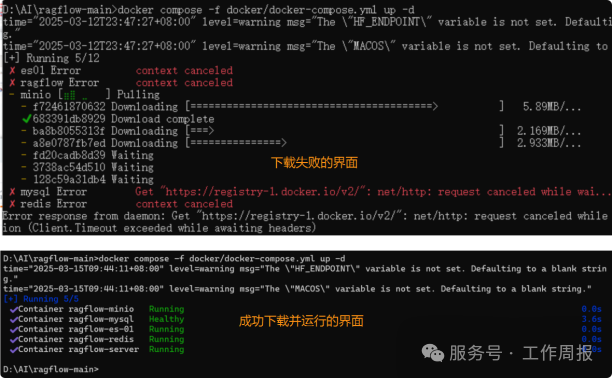
最后在docker的配置文件中加入一大堆镜像源,花费了很多个小时才下载完成。如果确实无法下载,可以尝试将docker desktop的配置文件修改成如下内容:
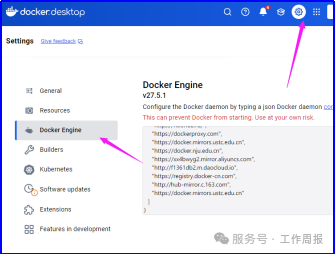
{"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"experimental": false,"max-concurrent-downloads": 3,"max-concurrent-uploads": 3,"max-download-attempts": 5,"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn>"],"shutdown-timeout": 150,"registry-mirrors":["https://docker.m.daocloud.io/","https://huecker.io/","https://dockerhub.timeweb.cloud","https://noohub.ru/","https://dockerproxy.com","https://docker.mirrors.ustc.edu.cn","https://docker.nju.edu.cn","https://xx4bwyg2.mirror.aliyuncs.com","http://f1361db2.m.daocloud.io","https://registry.docker-cn.com","http://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn"]}
3.6. 配置RAGflow
3.6.1. 在浏览器中输入:localhost:80,注册账户并登录RAGflow。这里其实是本机注册,邮箱密码可以写简单些。
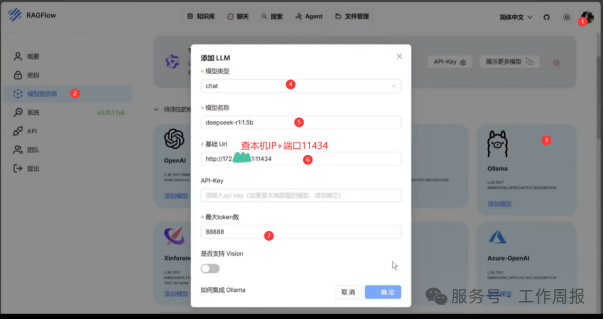
3.6.2. 登录后首先在RAGflow中添加模型
其中基础url的IP要写本机IP地址,不能写127.0.0.1,端口号写11434 最大token数随便写一下
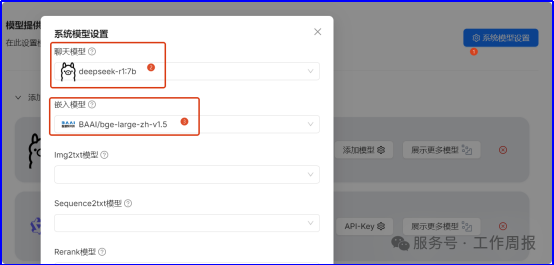
3.6.3. 然后在RAGflow中配置模型
分别配置聊天模型和嵌入模型,也就是向量化模型
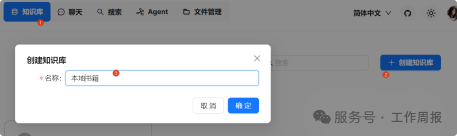
3.6.4. 然后在RAGflow中创建本地知识库
3.6.5. 然后配置知识库,主要是配置语言为中文
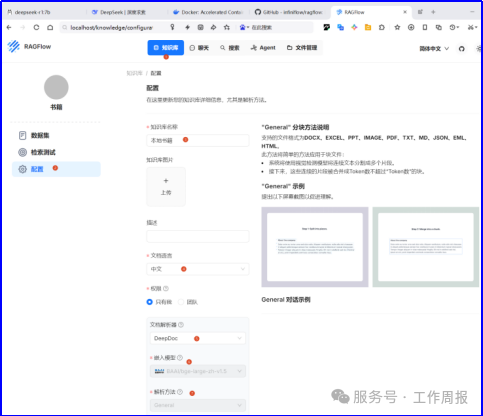
3.6.6. 然后配置数据集
上传本地文件,但是限制单个文件不超过10M,最多128个文件。 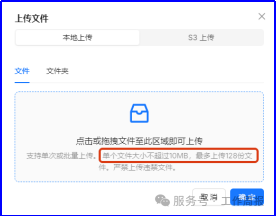
上传后对所有文件进行解析,也就是向量化,向量化后才能被LLM识别使用。 特别说明:解析过程很慢。
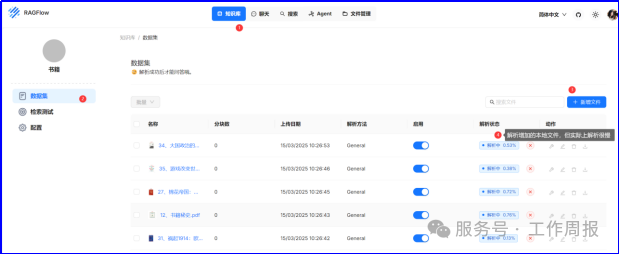
3.6.7. 然后设置聊天,建聊天助理,主要是为了指定知识库范围。因为实际上可以建立多个不同的知识库,设置多个聊天助理,这样就可以实现针对不同领域的私有知识库的智能对话。
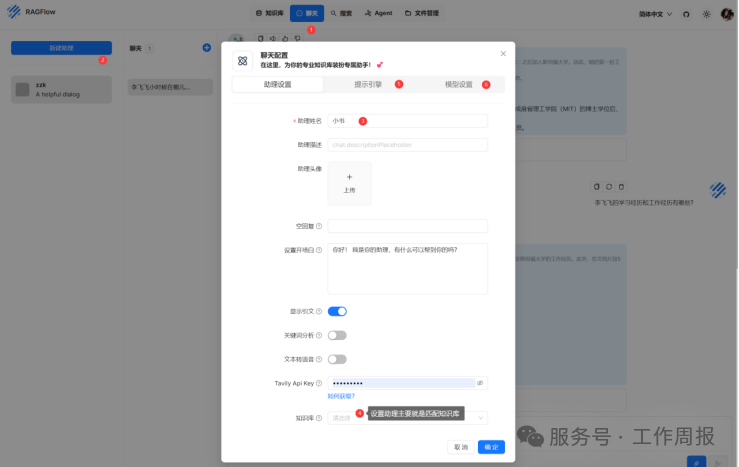
3.7. 终于可以基于本地的deepseek+Ragflow智能助理开始对话了,好激动...
实际聊天效果
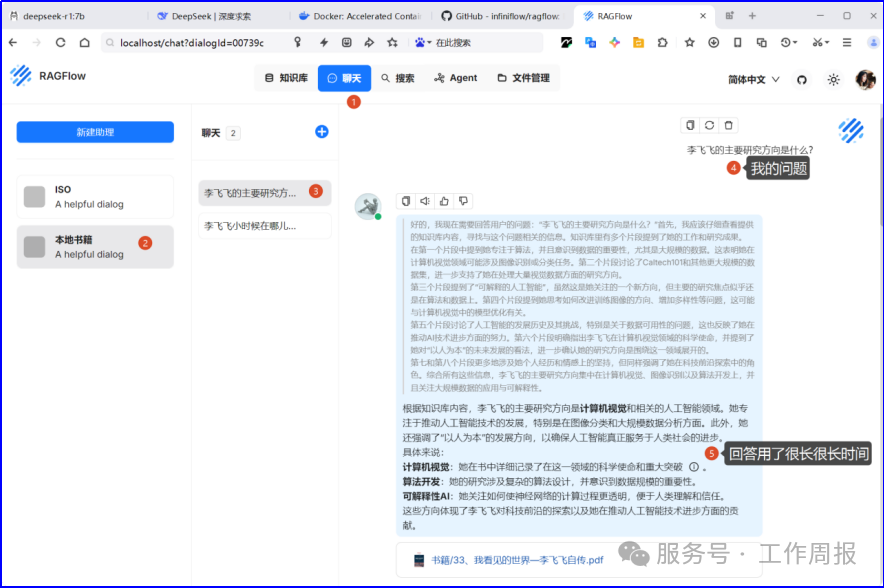
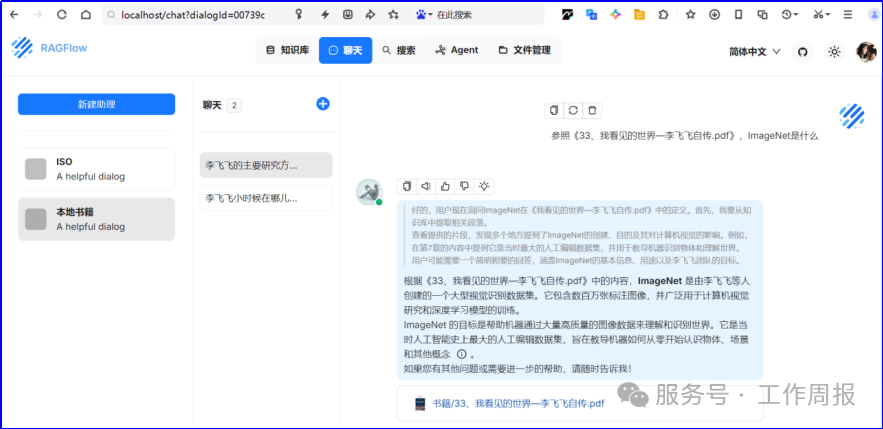
4. 总结:
4.1. 基于Deepseek+RAGflow的技术,可以实现基于个人笔记本电脑的私有AI助理。
4.2. 安装过程较为繁琐,实际上没有技术难度,但是下载的文件量很大,最少需要40G硬盘,10G以上内存,其中占用硬盘和内存最大的其实是docker,占用了90%以上的计算机资源。如果使用基于linux的docker应该会好非常多。
4.3. 最大的坑,有些文件下载让人抓狂,可能需要很长时间和很多耐心...
4.4. 不要担心笔记本电脑的硬件配置,实测在一台已使用5年的老笔记本电脑上也可以安装使用,当然速度确实慢,不过新电脑上速度也没快多少,再好的配置也会卡壳。电脑内存当然越大越好,不过显存和内存是可以共用的,也不必太担心。
4.5. 实际使用效果是:可用但不理想。
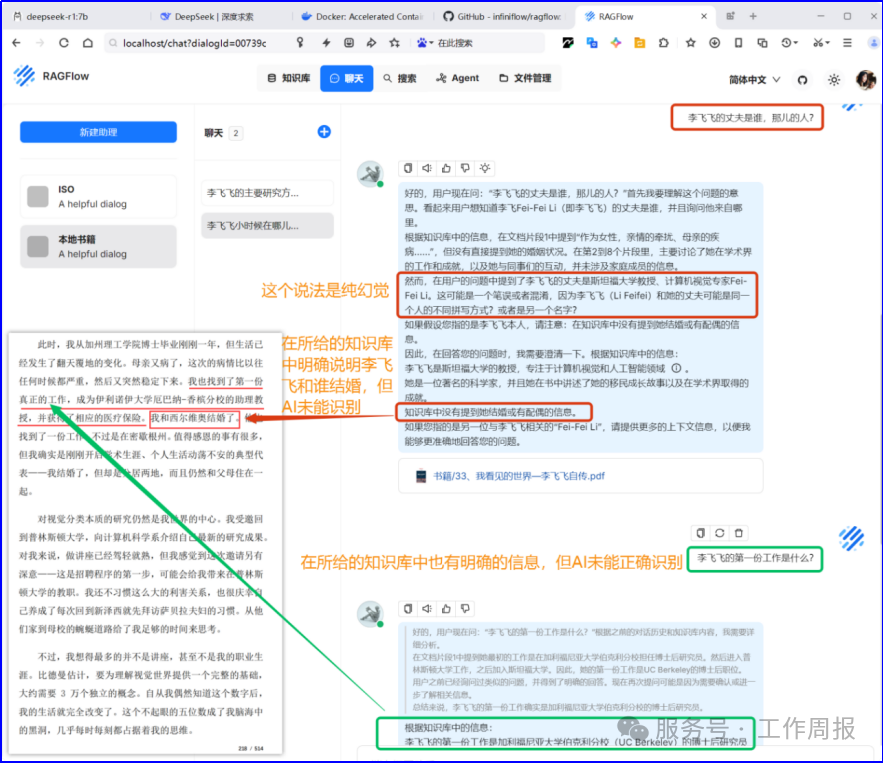
一是回答速度慢,实际上整个电脑都慢(罪魁祸首是docker)。 二是私有AI助理的总结能力不错,但精准回答很差,也有幻觉。
4.6. 从deepseek-r1:1.5b(1.1G)到从deepseek-r1:14b(9G),模型大小相差很多,但实际使用效果差不多。也许更大的模型效果会好吧,智能需要足够复杂的神经网络。
方案二:Deepseek+AnythingLLM
5. 方案简述:
在个人笔记本电脑上安装部署AI大模型Deepseek,配合模型应用工具AnythingLLM,建立个人或团队基于私有知识库的AI助手。
本地大模型(LLM):Deepseek,运行环境:windows11,作用是实现AI对话。
模型应用工具:AnythingLLM,运行环境:windows11,和RAGflow不同,不需要Docker Desktop,作用同样是实现本地知识库解析。
笔记本硬件:Thinkbook16+,Intel Ultra9+32G内存+NVIDIA GeForce RTX 4060(8G显存)
不得不说,AnythingLLM的方案安装和使用都简化太多了,真香!
7. 安装过程
7.1. 安装ollama
与RAGflow方案完全相同。
7.2. 下载DeepSeek
7.2.1. 与RAGflow方案完全相同。
7.2.2. AnythingLLM默认的工作目录是:C:\Users\用户名\AppData\Roaming\anythingllm-desktop\storage\models\ollama,下载的Deepseek模型也是存在这里,如果已经下载过模型不想再费时间下载一遍,也可以直接将模型文件拷贝到这里使用。
7.3. 下载安装AnythingLLM
7.3.1. 安装地址:https://anythingllm.com/desktop。
7.3.2. 不得不说AnythingLLM超级丝滑,下载后点击安装,直至安装完成后启动。
7.3.3. 配置大模型
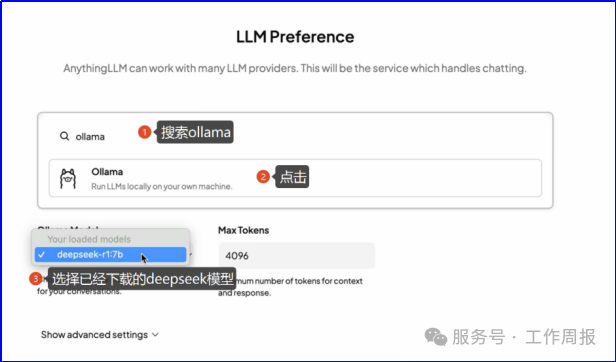
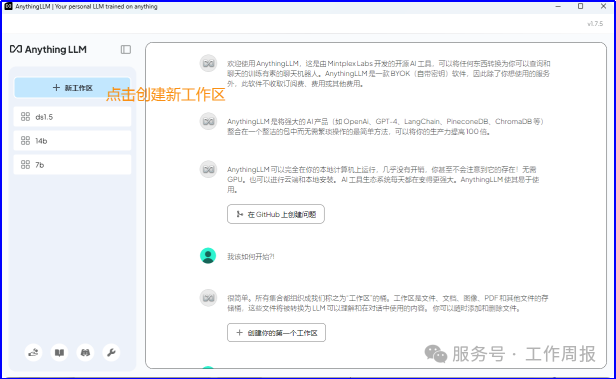
7.3.4. 创建工作区
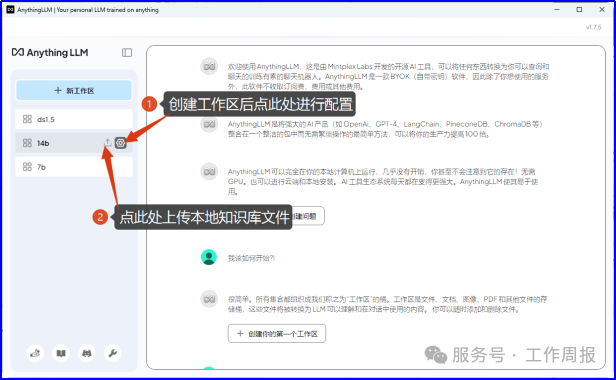
7.3.5. 配置工作区
7.3.6.上传本地知识库文档
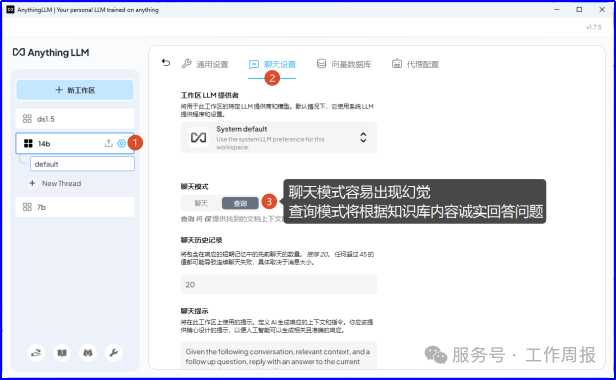
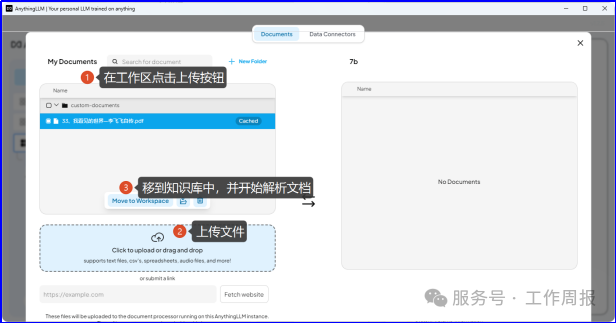
7.4. 开始使用deepseek+AnythingLLM
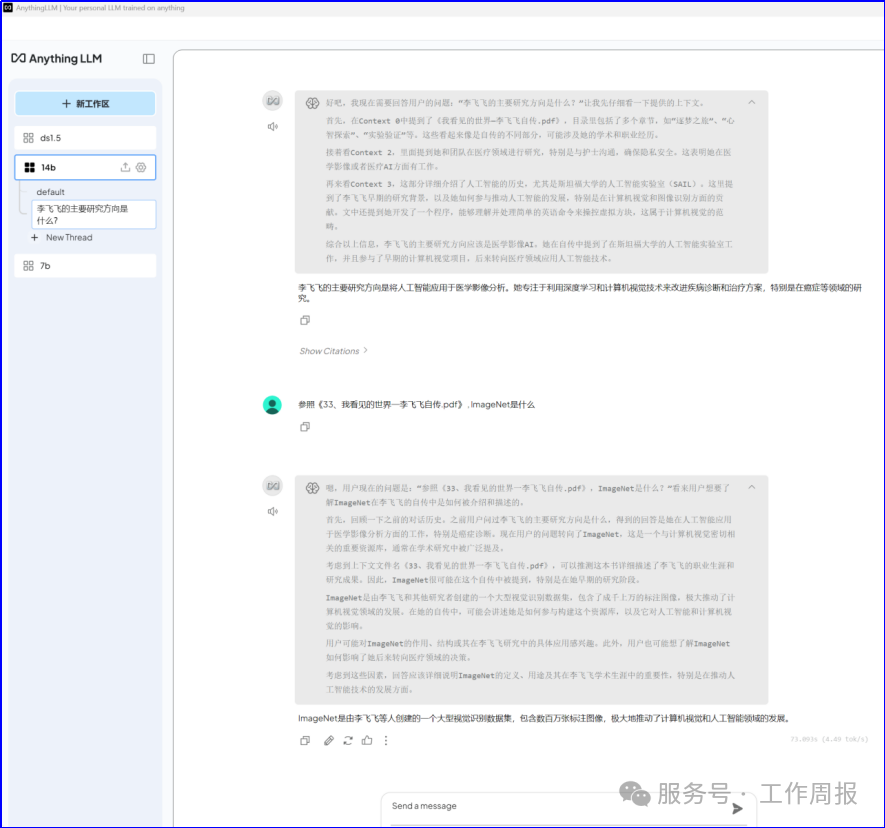
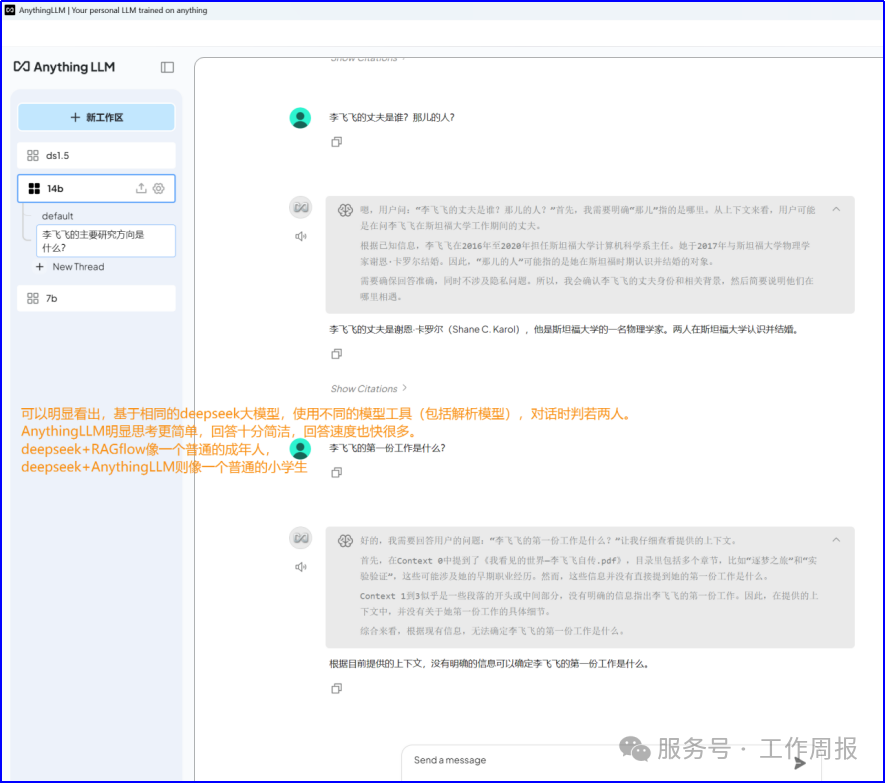
8. 总结
8.1. 基于Deepseek+AnythingLLM的技术,可以实现基于个人笔记本电脑的私有AI助理。
8.2. 安装过程简洁轻快,相对RAGflow方案资源占用少很多,运行速度很快。
8.3.实际使用效果是:可用但不理想。
可以明显看出,基于相同的deepseek大模型,使用不同的模型应用工具(包括解析模型),对话时判若两人。
AnythingLLM明显思考更简单,回答十分简洁,回答速度很快。
deepseek+RAGflow像一个普通的成年人。
deepseek+AnythingLLM像一个普通的小学生。
方案三:Deepseek+Dify
9. 方案简述:
在个人笔记本电脑上安装部署AI大模型Deepseek,配合模型应用工具Dify,建立个人或团队基于私有知识库的AI助手。
10. 技术环境:
本地大模型(LLM):Deepseek,运行环境:windows11,作用是实现AI对话。
模型应用工具:Dify,运行环境:windows11上的Docker Desktop,作用是实现本地知识库解析。
笔记本硬件:Thinkbook16+,Intel Ultra9+32G内存+NVIDIA GeForce RTX 4060(8G显存)
Dify的方案安装和使用都和RAGflow非常类似,消耗系统资源大,配置操作更加繁琐。故以下简述。
11. 安装过程
11.1. 安装ollama
与RAGflow方案完全相同。
11.2. 下载DeepSeek
与RAGflow方案完全相同。
11.3. 下载Docker
与RAGflow方案完全相同。
11.4. 下载Dify
11.4.1. 下载地址:https://docs.dify.ai/getting-started/install-self-hosted/docker-compose
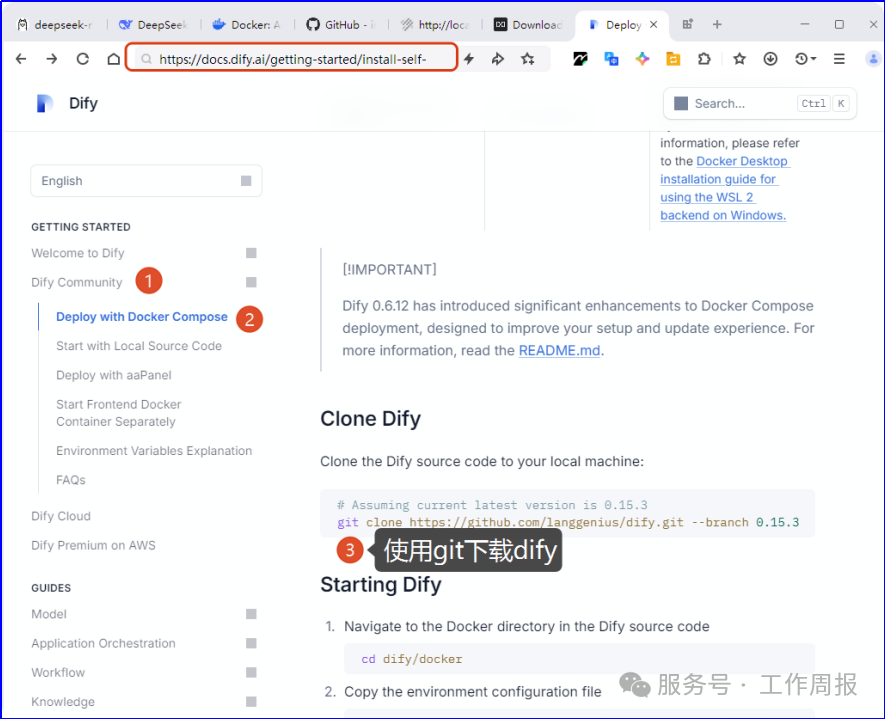
11.4.2. 在CMD窗口中执行下载命令
git clone https://github.com/langgenius/dify.git --branch 0.15.3执行这个命令需要本地安装了git。
11.4.3. 在CMD窗口中执行下载命令“docker compose up -d”,下载docker运行环境。下载过程和RAGflow一样,过程漫长,容易出错。
11.5. 配置Dify
11.4.1. 在浏览器中输入:localhost:80,注册账户并登录Dify。与RAGflow方案完全相同。
11.4.2.后续配置过程与RAGflow很类似,但操作更加繁琐。不再详述。建议非专业研究者了解即可。
11.4.3.以下截图仅供参考
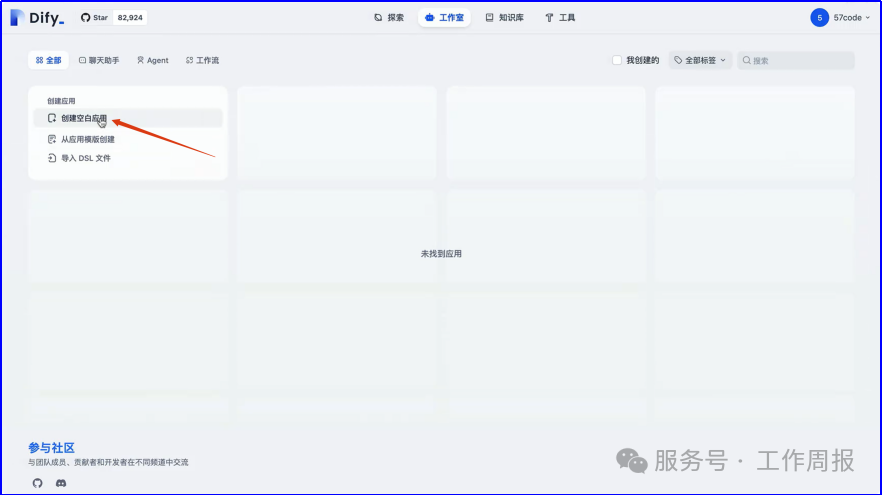
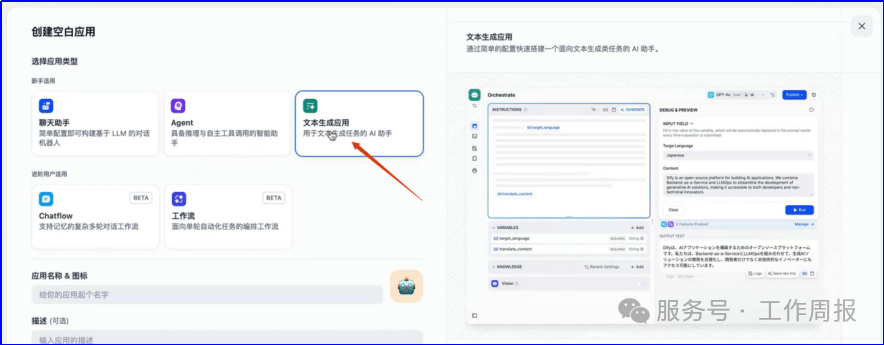
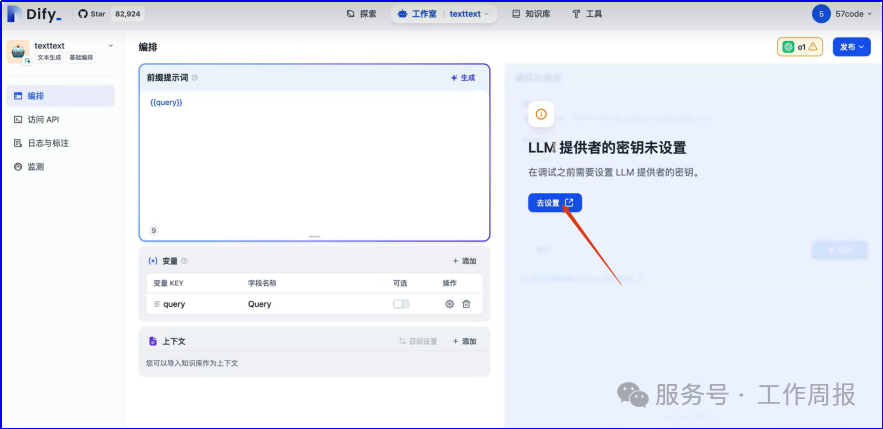
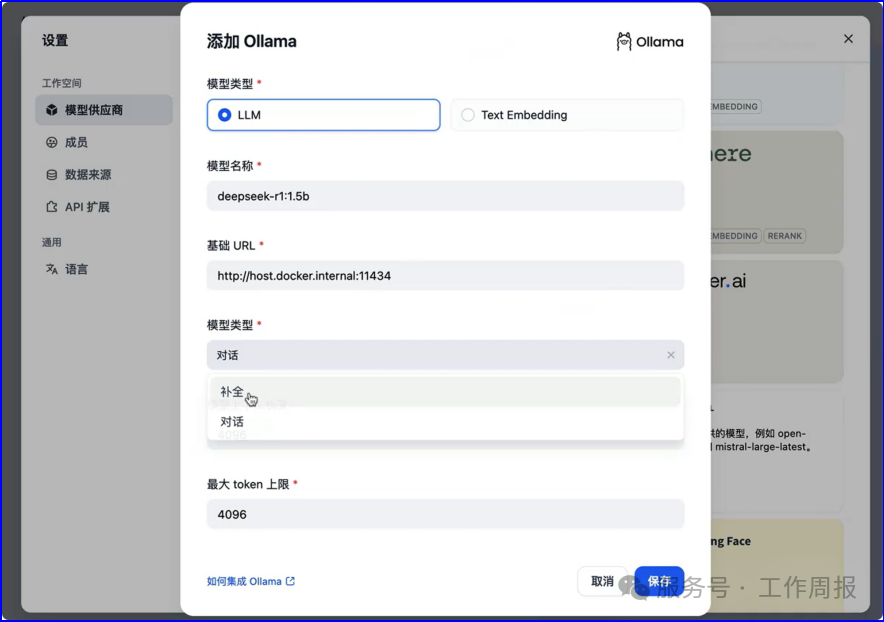
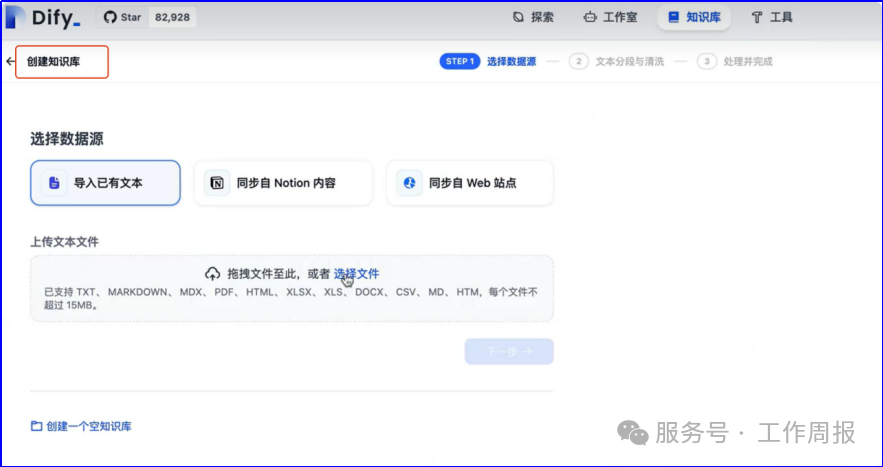
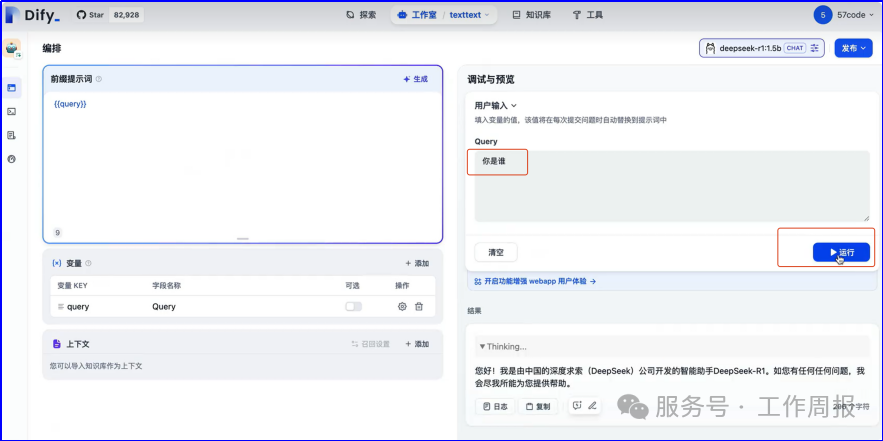
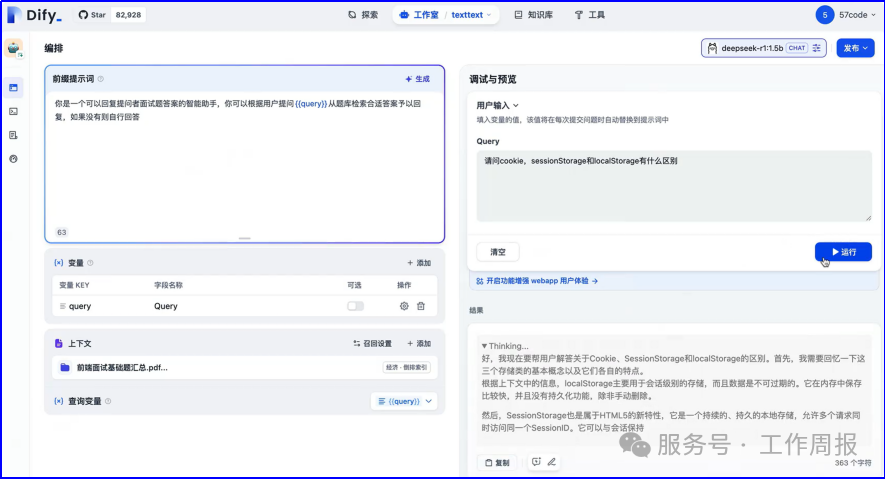
人工智能的发展已经显现出显著的飞轮效应,升级越来越快。
毫无疑问,私有部署的大模型一定没有在线的大模型好用。
但自己部署是一种学习方式,可以让我们对未来的理解稍微多一点点。
-END-
联系入群|加微信89931668
免费DeepSeek教程与学习资料




































请先 登录后发表评论 ~