

万字长文深度解读DeepSeek-V3技术要点

与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入!
近日,AI圈再度迎来重磅消息,DeepSeek团队正式发布了全新一代模型——DeepSeek-V3。这款模型不仅延续了“高性能、低成本”的传统,还首次开源了训练细节,迅速引发了业内的广泛关注。
Part 01 DeepSeek-V3有多强?

从表中可以看出,其成本控制远超竞争对手,尤其适合需要大规模调用的开发者和企业。
1、技术亮点:如何做到极致?
DeepSeek-V3的成功离不开其背后的技术创新。以下是论文中提到的几大核心亮点:
高效的MoE架构:通过动态激活37B参数,显著降低了计算成本,同时保证了模型性能。
大规模高质量数据训练:14.8T高质量数据的预训练,使模型在多任务场景下表现卓越。
优化的推理速度:生成速度提升3倍,每秒生成60个tokens,大幅提升了用户体验。
开源透明:首次公开训练细节,为研究者和开发者提供了宝贵的参考。
2、社区反响:一片赞誉
DeepSeek-V3的发布在社交媒体上引发热烈讨论,许多业内人士对其性能与成本的平衡表示赞叹:
Nikunj Kothari:“我觉得大家还没有意识到DeepSeek在智能与性价比上的优势。今天早上看到这个消息,简直惊呆了。”Dina Yerlan:“这对AI代理尤其重要,单元经济学的可持续性终于有了突破。”
Noorie:“真正的亮点是成本效率。”
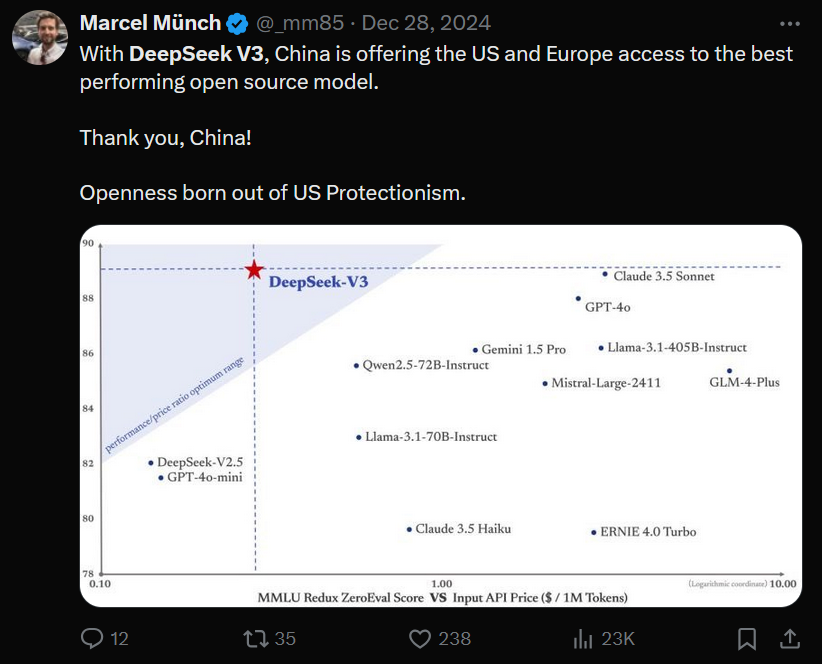
此外,DeepSeek-V3的发布也被视为开源AI领域的一次重要突破。正如Marcel Münch所言:“中国通过DeepSeek-V3为欧美市场提供了性能最强的开源模型。这是中国科技公司在美国保护主义下的胜利。”
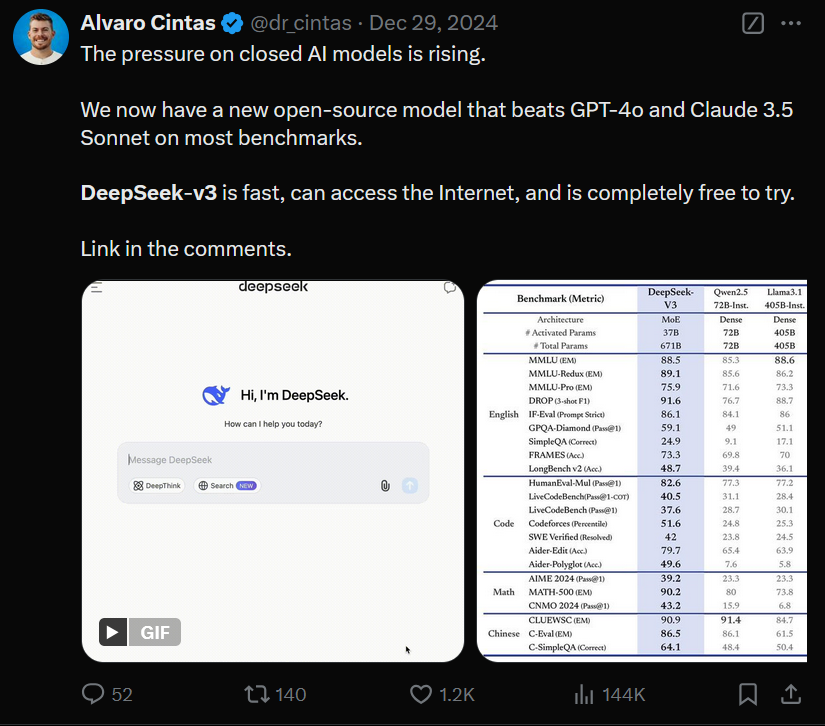
性能超越闭源模型
DeepSeek-V3在多个基准测试中击败了GPT-4o和Claude 3.5 Sonnet,成为开源领域的佼佼者。它不仅快,还支持联网功能,并且完全免费试用!
轻松部署,开发者友好
只需几行代码即可通过Gradio快速部署DeepSeek-V3,支持文本生成和代码辅助功能,极大降低了开发门槛:
高效算力利用,资源友好
运行半参数的DeepSeek-V2仅需7张80G A100显卡,占用490G显存。暗示着本地私有部署DeepSeek-V3也变为可能:
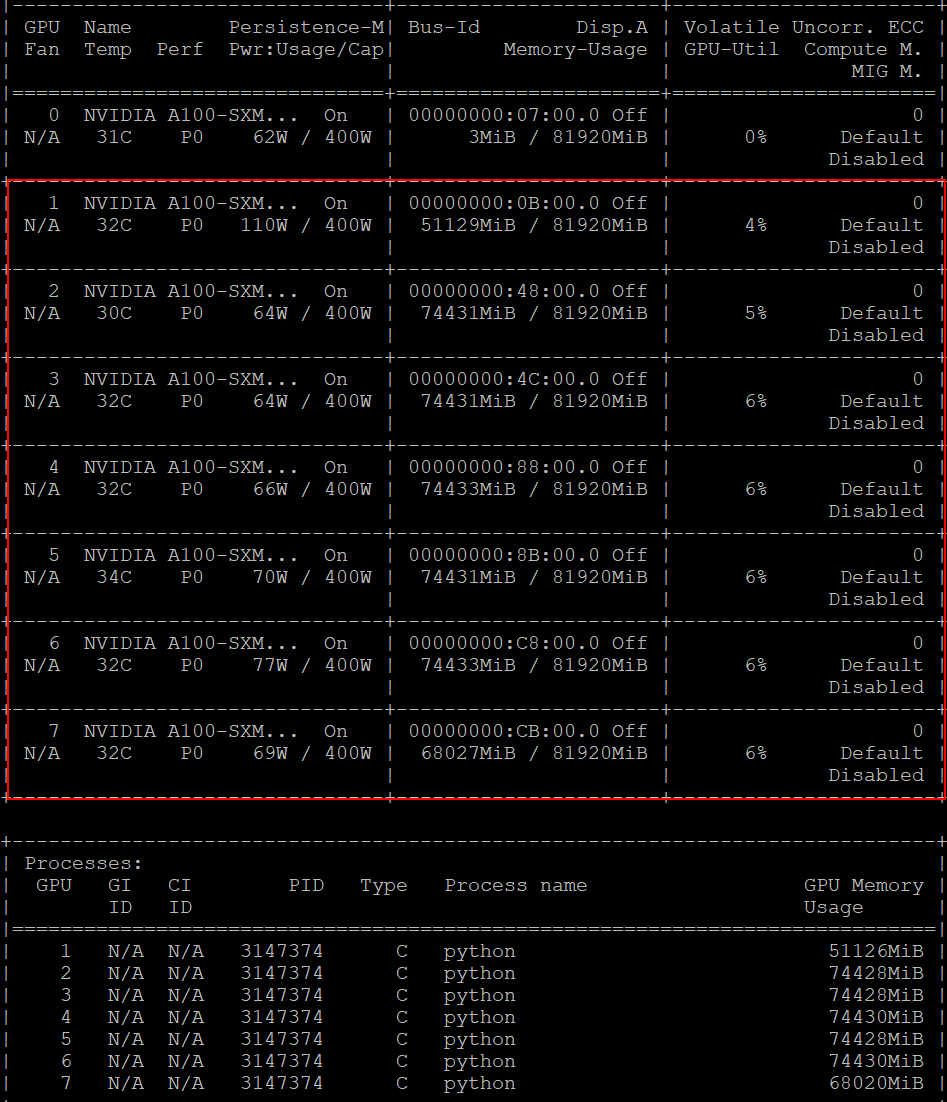
限时优惠,超值体验
DeepSeek-V3现已开放45天限时优惠体验期,让更多开发者以极低成本感受这款“性价比之王”的强大魅力。这款模型到底凭什么能在有限算力预算下做到如此极致?它的实际表现又如何?接下来,我们将为你详细解读这篇论文背后的技术亮点和实测效果!
Part 02 DeepSeek技术要点概览
1、DeepSeek-V3训练成本
DeepSeek-V3 的预训练阶段在不到两个月内完成,并花费了 2664K GPU 小时。加上 119K GPU 小时的上下文长度扩展和 5K GPU 小时的后训练,DeepSeek-V3 的完整训练成本仅为 2.788M GPU 小时。假设 H800 GPU 的租赁价格为每 GPU 小时 2 美元,总训练成本仅为 5.576M 美元。

2、DeepSeek-V3训练的核心阶段
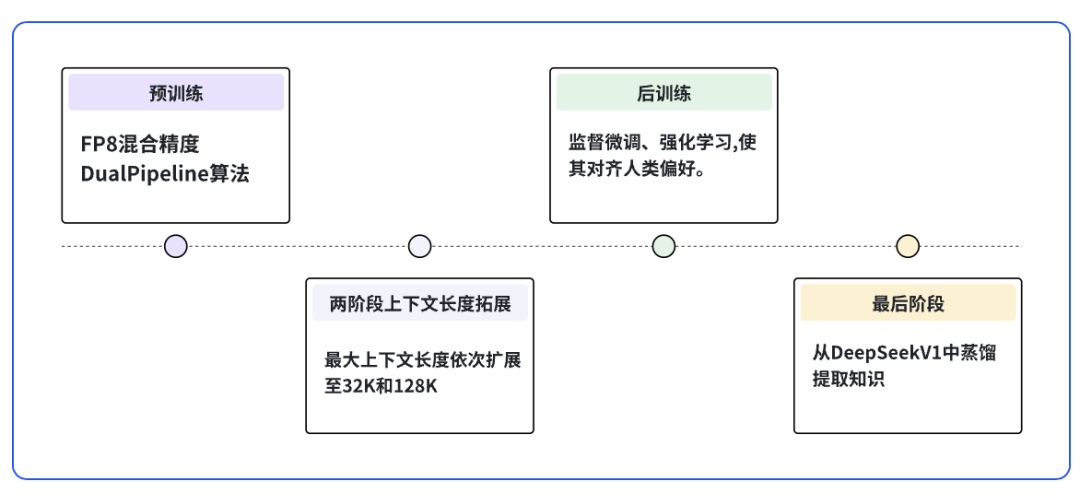
图1 DeepSeek-V3的核心阶段
3、训练流程
5、全面的训练框架优化
在训练框架方面,设计了DualPipe算法以优化流水线并行效率(efficient pipeline parallelism)。该算法通过计算与通信的重叠(computation-communication overlap),减少了流水线中的空闲时间(pipeline bubbles),并隐藏了大部分训练过程中的通信开销。
该算法减少了流水线气泡(pipeline bubbles)的数量,并通过计算-通信重叠隐藏了大部分通信开销。这种重叠确保了,随着模型的进一步扩展,只要保持恒定的计算-通信比率(constant computation-to-communication ratio),仍然可以在节点间(nodes)使用细粒度专家(fine-grained experts),同时实现接近零的全节点间通信开销(near-zero all-to-all communication overhead)。
开发了高效的跨节点全节点间通信内核(efficient cross-node all-to-all communication kernel),以充分利用 InfiniBand 和 NVLink 带宽。
精心优化了内存占用,使得在没有使用昂贵的张量并行(tensor parallelism)的情况下也能训练 DeepSeek-V3。
6、网络架构
DeepSeek-V3 的基本架构,包括 MLA 和 DeepSeekMoE 的关键组件。

图 2 DeepSeek-V3 的基本架构图
DeepSeek-V3 采用多头潜在注意力 (MLA) 架构进行高效的推理,并使用 DeepSeekMoE 架构进行经济的训练。此外,DeepSeek-V3 还引入了多 token 预测 (MTP) 训练目标,该目标已被证明可以提高模型在评估基准上的整体性能。除了这些主要特点,DeepSeek-V3 还遵循 DeepSeek-V2 的设置,例如 Transformer 框架、模型超参数、训练超参数等。
低秩联合压缩:MLA 通过对注意力键和值进行低秩联合压缩,来减少推理过程中的 Key-Value (KV) 缓存。
Rotary Positional Embedding (RoPE):MLA 使用 RoPE 来引入位置信息,并与压缩后的 KV 向量结合,以实现与标准多头注意力 (MHA) 相当的性能。
注意力查询压缩:MLA 对注意力查询也进行低秩压缩,以减少训练过程中的激活内存占用。
背景:Mix of Experts (MoE)
细粒度专家:DeepSeekMoE 使用细粒度专家,并将部分专家作为共享专家,以减少模型参数量和训练时间。 专家选择:DeepSeek-V3 使用门控机制来选择激活的专家。每个专家的激活概率由其与当前 token 的亲和度分数决定,并通过 sigmoid 函数计算。 无辅助损失式负载平衡:
对于混合专家模型(MoE),专家负载不平衡会导致路由崩溃(Shazeer等人,2017年[8])并在专家并行的情况下降低计算效率。传统的解决方案通常依赖于辅助损失(Fedus等人,2021年 [9];Lepikhin等人,2021年[10])来避免负载不平衡。然而,过大的辅助损失会损害模型性能(Wang等人,2024a [11])。为了在负载均衡和模型性能之间取得更好的平衡,首次提出了一种无辅助损失的负载均衡策略(Wang等人,2024a[11]),以确保负载均衡。具体来说,为每个专家引入了一个偏置项𝑏𝑖,并将其加到相应的亲和分数𝑠𝑖,𝑡上,以确定前K个路由。
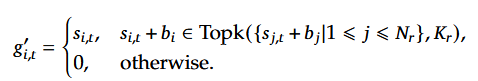
这样做的好处是:
避免路由崩溃:DeepSeek-V3 使用无辅助损失的负载平衡策略来避免 MoE 模型中路由崩溃的问题,该问题会导致专家负载不平衡并降低计算效率。
动态调整偏差:DeepSeek-V3 通过动态调整每个专家的偏差项来平衡专家负载,从而在负载平衡和模型性能之间取得更好的平衡。
序列级辅助损失:为了防止单个序列内出现极端不平衡,DeepSeek-V3 还使用了序列级辅助损失来鼓励每个序列上的专家负载平衡。
节点限制路由(Node-Limited Routing):限制训练过程中的通信成本。每个token最多被发送到M个节点,这些节点是根据每个节点上分布的专家的 highest 𝐾𝑟 affinity scores (每个节点上被激活的 𝐾𝑟 个专家中,与当前token关联性最高的专家的得分)选择的最优节点。这种机制保证了 MoE 训练框架能够近乎完全地实现计算-通信重叠,从而提高训练效率。
无token丢弃(No Token-Dropping): DeepSeek-V3 使用了有效的负载平衡策略,在训练过程中保持了良好的负载平衡。因此,DeepSeek-V3 在训练过程中不会丢弃任何token。
背景:Multi-Token Prediction
MTP是一种机制或方法论,它可以通过调整模型的目标函数、训练方式或推理策略来实现一次性预测多个标记的能力。它并不需要重新设计网络架构,而是基于现有的模型(如 Transformer)进行扩展或调整。MTP 的目标是通过引入额外的预测任务,让模型在每个深度k上预测未来的k-个标记。这种机制可以帮助模型更好地捕获上下文信息,并提升训练效率。
深度,实际上是指模型在预测未来标记时,预测的时间步数(或偏移量),而不是模型本身的层数或网络深度。设置不同的深度的目的是让模型能够在不同的时间步上预测未来的标记,从而增强模型对上下文的建模能力。
(4)DeepSeek-V3的MTP
受Gloeckle等人(2024年)[12] 的启发,对DeepSeek-V3进行了研究,并为其设置了多令牌预测(Multi-Token Prediction, MTP)目标。一方面,MTP目标增加了训练信号的密度,会提高数据效率。另一方面,MTP可能使模型能够预先规划其表示,以更好地预测未来的令牌。与Gloeckle等人(2024年)[12] 不同,他们使用独立的输出头并行预测D个额外的令牌,顺序预测额外的令牌,并在每个预测深度保持完整的因果链。
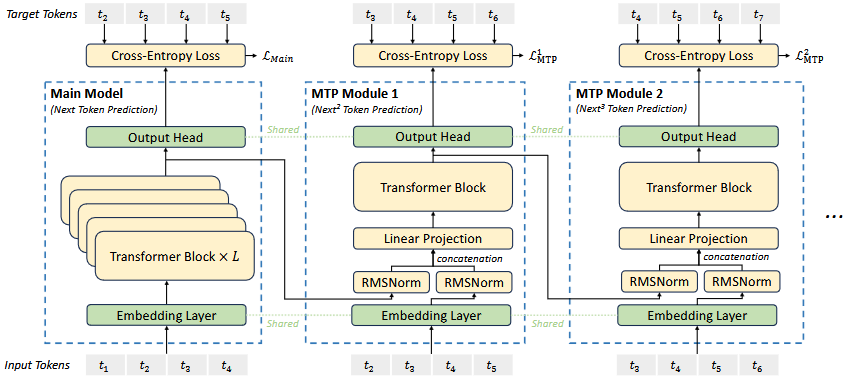
图 3: Multi-Token Prediction (MTP) 实现的示意图
MTP 的训练目标
MTP 的训练目标是最小化每个深度 k 的预测误差。对于第 k-层深度,使用交叉熵损失(CrossEntropy Loss)来衡量预测概率 Pk 与真实标记 t 之间的差异:
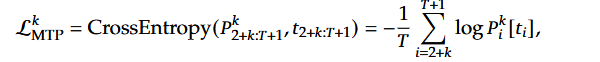
解释:
Pk[ti]:表示第k-层预测的第i-个标记的概率。
ti:表示第i-个位置的真实标记。
损失的计算范围是从位置 2+k 到T+1,因为第k-层需要预测的是未来的k-个标记。
将所有深度的 MTP 损失取平均,并乘以权重因子 λ 得到整体 MTP 损失:
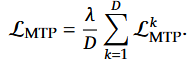
解释:
D:表示 MTP 模块的深度(即预测的标记数量)。
λ:用于平衡 MTP 损失与主任务损失的权重因子。
推理过程:可以直接丢弃 MTP 模块,主模型可以独立运行。此外,MTP 模块还可以用于推测解码,以进一步提高生成速度。
7、训练的硬件与软件配置
DeepSeek-V3 的训练由DeepSeek团队开发的 HAI-LLM 框架支持,这是一个高效且轻量级的框架。总体而言,DeepSeek-V3 使用 16 通道流水线并行 (Pipeline Parallelism,PP) (Qi et al., 2023a)[13]、64 通道专家并行 ( Expert Parallelism, EP) (Lepikhin et al., 2021) [14]跨越 8 个节点,以及 ZeRO-1 数据并行 (Data Parallelism, DP) (Rajbhandari et al., 2020)[15]。
注意力(Attention):Transformer 模型中的核心模块,用于捕获序列中不同位置之间的依赖关系。
全互联分发(All-to-All Dispatch):在分布式训练中,将数据从一个节点分发到多个节点的过程,通常用于专家模型(如 Mixture-of-Experts, MoE)中。
多层感知机(MLP):Transformer 中的前馈网络部分,用于对特征进行非线性变换。
全互联合并(All-to-All Combine):与全互联分发相对应,将多个节点的数据重新合并到一起。
特别地,对于反向计算块(Backward Chunk),注意力(Attention)和MLP部分会进一步拆分为两部分:针对输入的反向传播(Backward for Input),针对权重的反向传播(Backward for Weights)。这种拆分方式类似于 ZeroBubble 方法(Qi 等人,2023b)[16]。

图 4 | 一对单个前向和反向块的重叠策略(Transformer 块的边界不对应)。橙色表示前向,绿色表示“输入反向”,蓝色表示“权重反向”,紫色表示 PP 通信,红色表示障碍。
如图4 所示,对于一对前向和反向计算块,DualPipe 会对这些组件进行重新排列,并手动调整 GPU 流式多处理器(SM)在通信与计算之间的分配比例,确保通信和计算都能获得足够的资源支持。例如:
在通信密集的阶段,可以分配更多的 SM 资源给通信模块。
在计算密集的阶段,可以优先分配资源给计算模块。
通过这种重叠策略,可以确保:全互联通信(All-to-All Communication)和流水线通信(PP Communication)在执行过程中可以完全隐藏,从而避免通信开销对计算的影响。

基于这种高效的重叠策略,DualPipe 的完整调度流程如图 5 所示。它采用了一种双向流水线调度(Bidirectional Pipeline Scheduling),进一步提升了分布式训练的效率。具体特点如下:
双向微批次输入:从流水线的两端同时输入微批次(Micro-Batches)。传统的流水线调度通常是单向的,即从流水线的一端输入微批次(Micro-Batches)。DualPipe 则从流水线的两端同时输入微批次:一端输入前向计算的微批次,另一端输入反向计算的微批次。这种双向调度方式能够更高效地利用流水线资源,减少空闲时间。
通信与计算的重叠:大部分通信过程可以与计算完全重叠,从而显著减少通信开销。
DualPipe 的设计通过重叠计算与通信,结合双向流水线调度,显著提升了分布式训练的效率。其关键特性包括:
组件的拆分与重排;
手动调整计算与通信资源的分配;
高效的通信与计算重叠策略;
在大规模模型训练中实现近乎零的通信开销。
(2)高效的跨节点全到全通信实现
为了提升 DualPipe 的跨节点 All-to-All 通信效率,设计了专用通信内核,结合 MoE 的路由算法和集群拓扑优化通信性能。通过限制每个 token 最多分发到 4 个节点,减少了较慢的 IB 通信流量,并充分利用 NVLink 的高带宽,实现 IB 和 NVLink 通信的完全重叠。通信内核使用 20 个 SM,分为 10 个动态调整的通信通道,分别处理 IB 和 NVLink 的发送、转发和接收任务,同时与计算流重叠以减少干扰。通过自定义 PTX 指令和自动调优通信块大小,进一步优化了 L2 缓存使用和 SM 资源分配。
(3)FP8低精度训练
低精度训练虽然在提升计算效率和降低内存占用方面具有巨大潜力,但其应用往往受到激活值、权重和梯度中的异常值(outliers)的限制。尽管推理阶段的量化技术已经取得显著进展,但在大规模语言模型的预训练中,低精度技术的成功应用仍然较少。
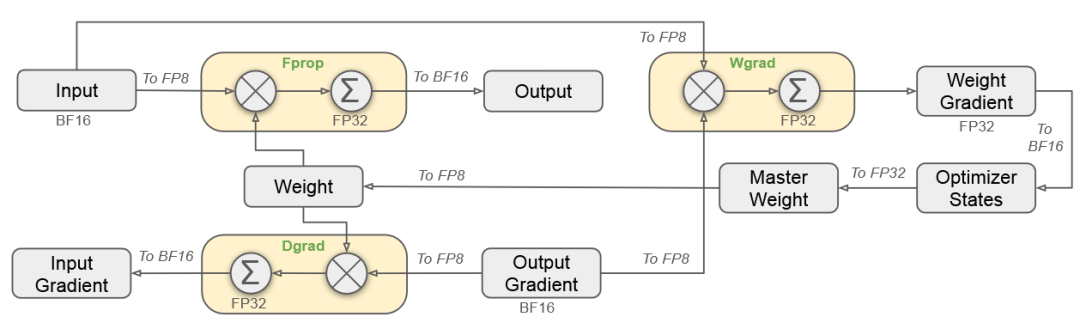
研究团队提出了一种基于FP8的混合精度训练框架,用于高效训练大规模语言模型DeepSeek-V3。框架通过在不同阶段灵活使用FP8、BF16和FP32格式,显著降低计算和内存开销,同时保持训练精度。
核心设计
前向传播(Fprop):输入和权重以FP8格式计算,累加操作使用FP32,输出以BF16存储。
反向传播(Dgrad & Wgrad):梯度计算同样采用FP8矩阵运算,累加过程保持FP32精度。
权重更新:主权重以FP32存储,优化器状态以BF16存储,权重更新后转为FP8。
关键优化
FP8计算:降低计算和通信开销。
FP32累加(高精度累加):避免低精度误差积累。
BF16存储:减少内存占用。
为了克服 FP8 格式动态范围有限的问题,本文提出了一种细粒度量化策略:
Tile-wise 分组:每组包含 1×Nc个元素。
Block-wise 分组:每组包含Nc×Nc个元素。
这种分组策略能够有效扩展 FP8 的动态范围,同时通过高精度累加过程(increased-precision accumulation)显著降低量化和反量化的开销,从而实现高精度的 FP8 通用矩阵乘法(GEMM)。
8、实验结果
本文在两个模型规模(分别类似于 DeepSeek-V2-Lite 和 DeepSeek-V2)上验证了所提出的 FP8 混合精度框架,训练数据量约为 1 万亿 tokens。实验结果表明:与 BF16 基线相比,FP8 训练模型的相对损失误差始终低于 0.25%,这一误差水平完全在训练随机性的可接受范围内。
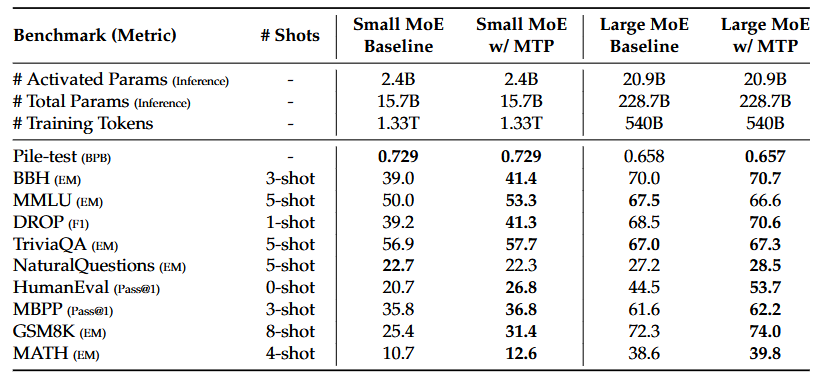
(1)多标记预测的消融研究
在两个基线模型(小规模15.7B参数、大规模228.7B参数)上加入MTP模块,保持训练数据和其他架构不变。推理时直接移除MTP模块,确保推理成本一致。MTP策略在大多数评估基准上显著提升了模型性能。
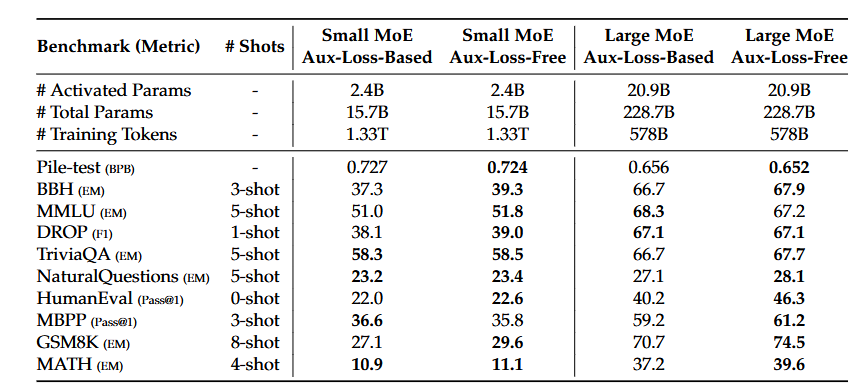
(2)辅助损失自由(Auxiliary-Loss-Free)策略的消融研究
基线模型均使用传统的辅助损失机制来实现负载平衡,采用sigmoid门控函数和top-K亲和度归一化。其辅助损失的超参数设置与DeepSeek-V2-Lite和DeepSeek-V2一致。在此基础上,移除所有辅助损失机制,改用辅助损失自由策略,同时保持训练数据和其他架构不变。表3显示,辅助损失自由策略在大多数评估基准上均显著提升了模型性能。
(3)强化学习奖励模型总结
在强化学习中,采用两种奖励模型:基于规则的奖励模型和基于模型的奖励模型。
基于规则的奖励模型
用于可通过规则验证的问题(如数学题和LeetCode问题),通过指定格式或编译器测试确保答案的可靠性,避免奖励被操控。
基于模型的奖励模型
用于自由形式答案的问题,依赖模型判断答案的匹配度。通过引入偏好数据和推理过程(Chain-of-Thought)训练奖励模型,提升可靠性并降低奖励滥用风险。
采用了群体相对策略优化(Group Relative Policy Optimization,GRPO),这一方法源于DeepSeek-V2,摒弃了传统与策略模型同规模的价值函数模型(critic model),而是通过群体得分估计基线值。在强化学习过程中,使用来自多领域(如编程、数学、写作、角色扮演和问答)的提示词,提升模型对人类偏好的对齐能力。GRPO方法在有限的监督微调(SFT)数据场景下,显著提升了模型在基准测试中的表现。
9、优化方法总结
(1)从 DeepSeek-R1 的蒸馏学习
基于 DeepSeek-V2.5,研究了从 DeepSeek-R1 的蒸馏数据对模型性能的贡献。对比实验中,基线模型仅使用短推理链(CoT)数据训练,而对比模型则使用由专家检查点生成的蒸馏数据。实验结果表明,蒸馏数据显著提升了 LiveCodeBench 和 MATH-500 基准测试的性能。蒸馏数据的引入虽然提升了性能,但也显著增加了平均响应长度。
(2)自奖励机制(Self-Rewarding)
奖励机制是强化学习(RL)的核心。在某些领域(如编程和数学),通过外部工具验证答案较为简单,RL效果显著。但在更广泛的场景中,构建硬编码反馈机制并不现实。在DeepSeek-V3的开发中,采用 宪法式 AI(Constitutional AI)方法,利用模型自身的投票评估结果作为反馈来源,这种方法显著提升了模型在主观评估中的表现。通过引入额外的宪法式输入,模型能够进一步优化其方向。
(3)多Token预测评估(Multi-Token Prediction, MTP)
DeepSeek-V3 不仅预测下一个单一Token,还通过 多Token预测(MTP) 技术预测接下来的两个Token。结合 推测解码(Speculative Decoding) 框架,这一方法显著加速了模型的解码速度。MTP 技术结合推测解码,为提升生成速度提供了高效解决方案,同时保持了生成质量的稳定性。
Part 03 结束语
综合评估显示,DeepSeek-V3 成为当前最强的开源模型,其性能媲美闭源模型(如 GPT-4o 和 Claude-3.5-Sonnet),同时保持了经济的训练成本。尽管性能卓越,DeepSeek-V3 在部署上仍有一定局限性,例如推荐部署单元较大可能对小型团队造成资源压力,且推理速度仍有优化空间。不过,随着硬件技术的进步,这些问题预计将逐步解决。
据悉,作为一个长期主义的开源项目,DeepSeek 致力于迈向通用人工智能(AGI)。未来研究将聚焦于优化模型架构、提升训练与推理效率、支持无限上下文长度、突破 Transformer 架构限制,并扩展训练数据的数量与质量。同时,团队将专注于增强模型的深度推理能力,提升智能性与问题解决能力,并探索更全面的多维度评估方法,避免过度优化固定基准测试。
总体而言,DeepSeek-V3 凭借创新设计、经济高效的训练策略和卓越性能,已成为开源领域的领先模型。未来,期待团队继续深耕模型架构、数据扩展、推理能力和评估方法,为实现 AGI 奠定坚实基础。
作者:邢文鹏,韩蒙
排版:荷尖儿
审校:李昱锋,王哲博
引用:
[1] DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. CoRR, abs/2405.04434, 2024c. URL https://doi.org/10.48550/arXiv.2405.04434.066
[2] D. Dai, C. Deng, C. Zhao, R. X. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y. Wu, Z. Xie, Y. K.Li, P. Huang, F. Luo, C. Ruan, Z. Sui, and W. Liang. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. CoRR, abs/2401.06066, 2024. URL
https://doi.org/10.48550/arXiv.2401.06066.
[3] L. Wang, H. Gao, C. Zhao, X. Sun, and D. Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts. CoRR, abs/2408.15664, 2024a. URL https://doi.org/10.48550/arX
iv.2408.15664
[4] T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in Neural Information Processing Systems, 35:30318–30332, 2022.
[5] D. Kalamkar, D. Mudigere, N. Mellempudi, D. Das, K. Banerjee, S. Avancha, D. T. Vooturi,N. Jammalamadaka, J. Huang, H. Yuen, et al. A study of bfloat16 for deep learning training.arXiv preprint arXiv:1905.12322, 2019.
[6] H. Peng, K. Wu, Y. Wei, G. Zhao, Y. Yang, Z. Liu, Y. Xiong, Z. Yang, B. Ni, J. Hu, et al. FP8-LM:
Training FP8 large language models. arXiv preprint arXiv:2310.18313, 2023b.
[7] S. Narang, G. Diamos, E. Elsen, P. Micikevicius, J. Alben, D. Garcia, B. Ginsburg, M. Hous-
ton, O. Kuchaiev, G. Venkatesh, et al. Mixed precision training. In Int. Conf. on Learning Representation, 2017.
[8] N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V. Le, G. E. Hinton, and J. Dean. Outrageously
large neural networks: The sparsely-gated mixture-of-experts layer. In 5th International
Conference on Learning Representations, ICLR 2017. OpenReview.net, 2017. URL https://openreview.net/forum?id=B1ckMDqlg.
[9] W. Fedus, B. Zoph, and N. Shazeer. Switch transformers: Scaling to trillion parameter models
with simple and efficient sparsity. CoRR, abs/2101.03961, 2021. URL https://arxiv.org/abs/2101.03961.
[10] D. Lepikhin, H. Lee, Y. Xu, D. Chen, O. Firat, Y. Huang, M. Krikun, N. Shazeer, and Z. Chen.
Gshard: Scaling giant models with conditional computation and automatic sharding. In 9th
International Conference on Learning Representations, ICLR 2021. OpenReview.net, 2021.
URL https://openreview.net/forum?id=qrwe7XHTmYb
[11] L. Wang, H. Gao, C. Zhao, X. Sun, and D. Dai. Auxiliary-loss-free load balancing strategy for
mixture-of-experts. CoRR, abs/2408.15664, 2024a. URL https://doi.org/10.48550/arX
iv.2408.15664.
[12] F. Gloeckle, B. Y. Idrissi, B. Rozière, D. Lopez-Paz, and G. Synnaeve. Better & faster large
language models via multi-token prediction. In Forty-first International Conference on
Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL
https://openreview.net/forum?id=pEWAcejiU2
[13] P. Qi, X. Wan, G. Huang, and M. Lin. Zero bubble pipeline parallelism. arXiv preprint
arXiv:2401.10241, 2023a.
[14] D. Lepikhin, H. Lee, Y. Xu, D. Chen, O. Firat, Y. Huang, M. Krikun, N. Shazeer, and Z. Chen.
Gshard: Scaling giant models with conditional computation and automatic sharding. In 9th
International Conference on Learning Representations, ICLR 2021. OpenReview.net, 2021.
URL https://openreview.net/forum?id=qrwe7XHTmYb.
[15] S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He. Zero: Memory optimizations toward training tril-
lion parameter models. In SC20: International Conference for High Performance Computing,
Networking, Storage and Analysis, pages 1–16. IEEE, 2020.
[16] P. Qi, X. Wan, G. Huang, and M. Lin. Zero bubble pipeline parallelism, 2023b. URL https:
//arxiv.org/abs/2401.10241.


































请先 登录后发表评论 ~