

DeepSeek“开源周”第二天开源项目—DeepEP

DeepSeek AI开启了为期一周的开源周活动(Day 2 of #OpenSourceWeek: DeepEP),第二日推出了 DeepEP 项目。
DeepSeek AI(深度求索)开启了为期一周的开源周活动#OpenSourceWeek,首日推出了 DeepEP 项目。这是一个专为 Mixture-of-Experts (MoE) 和专家并行 (EP) 量身定制的高效通信库,将为您的模型训练和推理任务带来前所未有的加速体验!


01.
开源项目介绍
DeepEP
DeepEP 是一个针对 MoE 和专家并行的通信库,提供了高吞吐量和低延迟的 all-to-all GPU 内核,这些内核也被称为 MoE 分发和合并。它支持低精度操作,包括 FP8,能够满足不同场景下的性能需求。为了与 DeepSeek-V3 论文中提出的组限门控算法保持一致,DeepEP 还提供了一套针对不对称域带宽转发优化的内核,例如从 NVLink 域到 RDMA 域的数据转发。这些内核具有高吞吐量,非常适合训练和推理预填充任务,并且支持 SM(流式多处理器)数量控制。
对于延迟敏感的推理解码任务,DeepEP 包含了一套低延迟内核,采用纯 RDMA 以最小化延迟。此外,该库还引入了一种基于钩子的通信计算重叠方法,不会占用任何 SM 资源。
开源地址:https://github.com/deepseek-ai/DeepEP
开源协议:MIT license
项目亮点
高吞吐量与低延迟:DeepEP 提供的 all-to-all GPU 内核在高吞吐量和低延迟方面表现出色,能够满足 MoE 和 EP 场景下的通信需求。
低精度操作支持:支持 FP8 等低精度操作,有助于减少计算资源消耗,提高模型训练和推理效率。
优化的不对称域带宽转发:针对 NVLink 域到 RDMA 域的数据转发进行了优化,提供高吞吐量的内核,适合训练和推理预填充任务。
低延迟内核:为延迟敏感的推理解码任务提供了低延迟内核,采用纯 RDMA,最小化延迟。
通信计算重叠:引入基于钩子的通信计算重叠方法,不占用 SM 资源,提高计算资源利用率。
02.
性能表现
正常内核
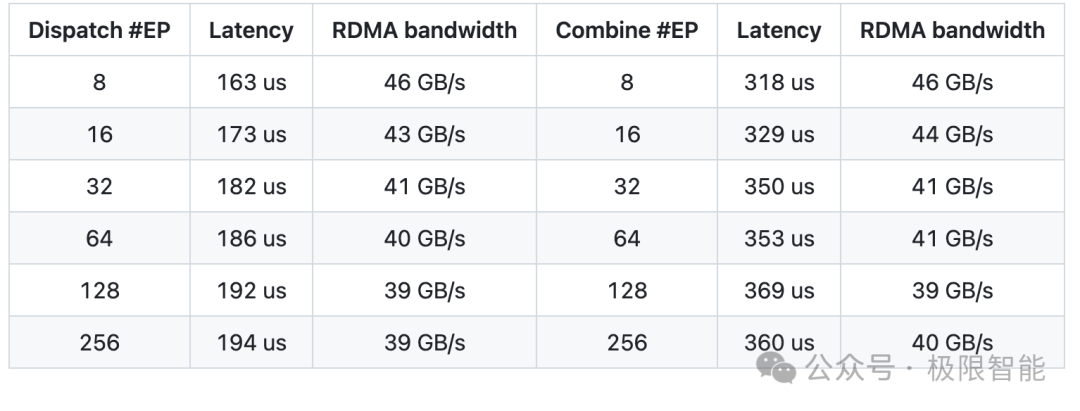
在 H800 GPU(约 160 GB/s NVLink 最大带宽)上进行测试,每个 GPU 连接到一个 CX7 InfiniBand 400 Gb/s RDMA 网卡(约 50 GB/s 最大带宽)。按照 DeepSeek-V3/R1 预训练设置(每批 4096 个 token,7168 个隐藏单元,top-4 组,top-8 专家,FP8 分发和 BF16 合并),测试结果如下:

低延迟内核
在 H800 GPU 上进行测试,每个 GPU 连接到一个 CX7 InfiniBand 400 Gb/s RDMA 网卡(约 50 GB/s 最大带宽)。按照典型的 DeepSeek-V3/R1 生产设置(每批 128 个 token,7168 个隐藏单元,top-8 专家,FP8 分发和 BF16 合并),测试结果如下:
结束
入群联系|加微信89931668
免费DeepSeek教程与学习资料



































请先 登录后发表评论 ~