

DeepSeek开源周第三波: 专为FP8设计的DeepGEMM,核心代码仅300行!

开源周进行到第三天,DeepSeek不仅带来了技术,还传出R2在路上的好消息。据多位知情人士透露,DeepSeek 正在加速推出 R1 强推理大模型的后续版本。其中有两人表示,DeepSeek 原本计划在 5 月初发布 R2,但现在希望尽早发布。DeepSeek 希望新模型拥有更强大的代码生成能力,并能够推理除英语以外的语言。
今天开源的项目名叫 DeepGEMM,是一款支持密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了支持,在 Hopper GPU 上可以达到 1350+ FP8 TFLOPS 的计算性能。
开源地址:https://github.com/deepseek-ai/DeepGEMM

一、DeepGEMM的亮点
GEMM,即通用矩阵乘法,是线性代数中的基本运算,是科学计算、机器学习、深度学习等领域中“常客”,也是许多高性能计算任务的核心。
而DeepSeek这次开源的DeepGEMM,依旧是保持了“高性能+低成本”的特性,亮点如下:
高性能:在Hopper架构的GPU上,DeepGEMM能够实现高达1350+FP8 TFLOPS的性能。
简洁性:核心逻辑仅约 300 行代码,在各种矩阵形状上的性能与专家调优的库相当,甚至在某些情况下更优。
即时编译(JIT):采用完全即时编译的方式,这意味着它可以在运行时动态生成优化的代码,从而适应不同的硬件和矩阵大小。
无重依赖:这个库设计得非常轻量级,没有复杂的依赖关系,可以让部署和使用变得简单。
支持多种矩阵布局:支持密集矩阵布局和两种 MoE 布局,这使得它能够适应不同的应用场景,包括但不限于深度学习中的混合专家模型。
二、DeepGEMM的性能如何?
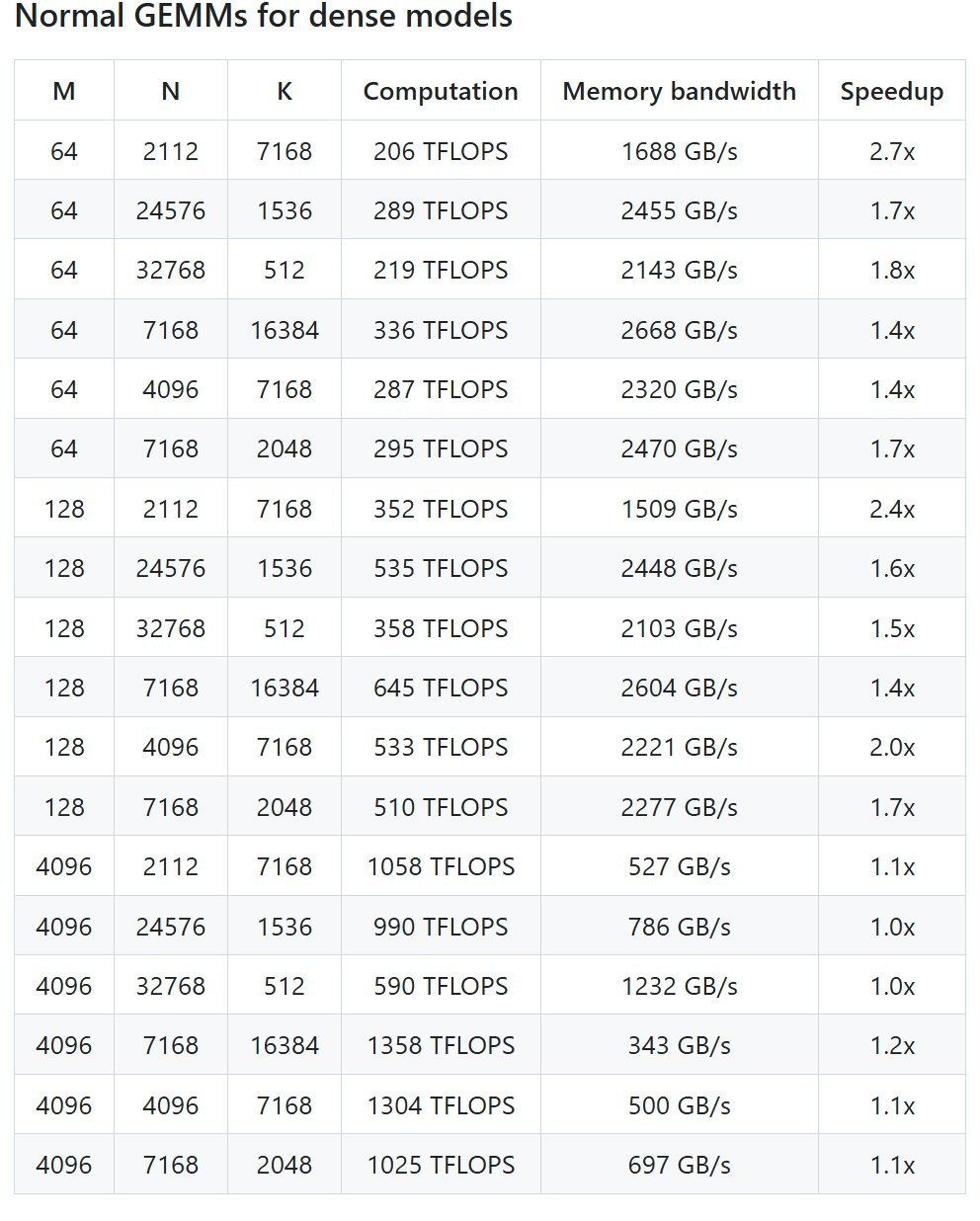
DeepSeek 在 H800 上使用 NVCC 12.8 测试了 DeepSeek-V3/R1 推理中可能使用的所有形状(包括预填充和解码,但不包括张量并行),最高可以实现 2.7 倍加速。所有加速指标均基于内部精心优化的 CUTLASS 3.6 实现。
但根据项目介绍,DeepGEMM 在某些特定矩阵形状下的表现不够理想,有待优化。
密集模型的标准 GEMM
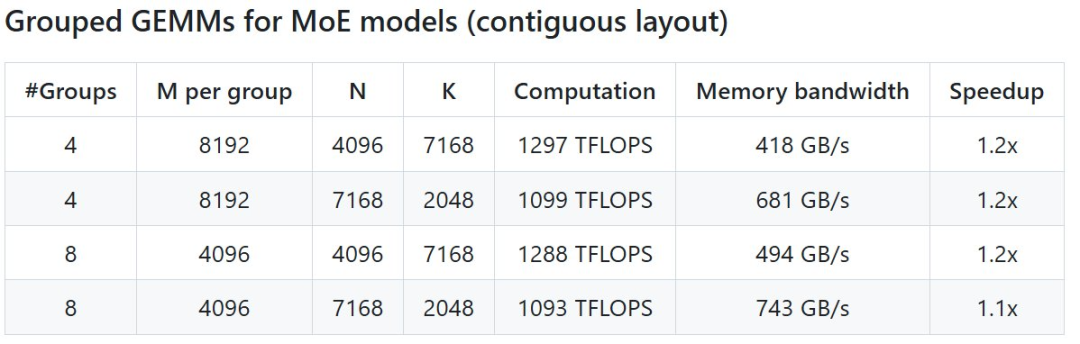
MoE 模型的分组 GEMM(连续布局)
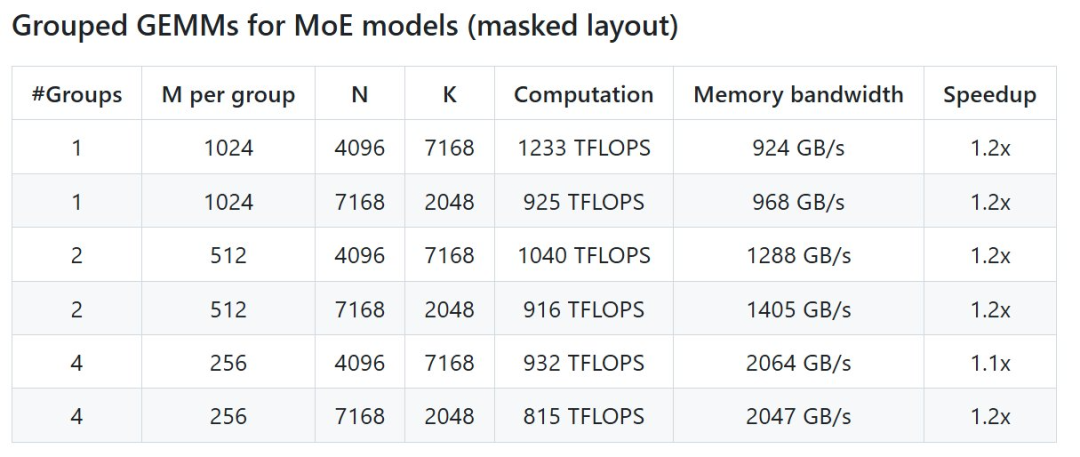
MoE 模型的分组 GEMM(掩码布局)
三、DeepGEMM如何快速布局?
首先需要以下配置:
Hopper 架构的 GPU,必须支持 sm_90a;
Python 3.8 或更高版本;
CUDA 12.3 或更高版本,但为了获得最佳性能,DeepSeek 强烈推荐使用 12.8 或更高版本;
PyTorch 2.1 或更高版本;
CUTLASS 3.6 或更高版本(可通过 Git 子模块克隆)。
-END-
入群联系|加微信89931668
免费DeepSeek教程与学习资料


































请先 登录后发表评论 ~