

大白话讲解什么是多模态大模型

当我们说起多模态大模型,我们说的是模型的输入输出可以支持什么形式?
但是,大家都有的问题是,对于不同形态的输入,它们是怎么一起合作来实现共同理解的?所以我们可以以图文这种最常见的组合来看看多模态大模型是怎么工作的。
认识多模态LLM
想象你有一个超级助手,他不仅能读懂文字,还能看懂图片,更厉害的是能把看到的和读到的信息结合起来思考。这就是多模态LLM,简单来说就是既能看又能读的AI。"多模态"其实就是"多种方式"的意思,就像我们人类使用眼睛和大脑一样自然。
1.它是如何"看"图片的
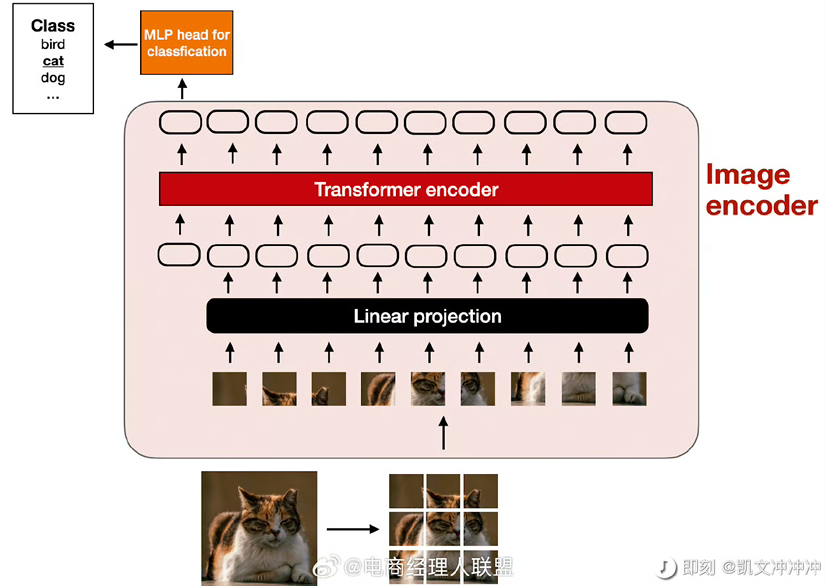
图一。这个过程就像在玩拼图。首先,它会把一张大图片切成很多小方块(每块16×16像素),就像把一张全家福照片切成小块。然后,它会仔细"看"每个小方块,理解里面有什么,同时记住每个小块在原图中的位置。最后,它会把看到的所有信息转换成数字,这些数字就像是图片的"密码",电脑可以理解的语言。
2.图片和文字是如何结合的
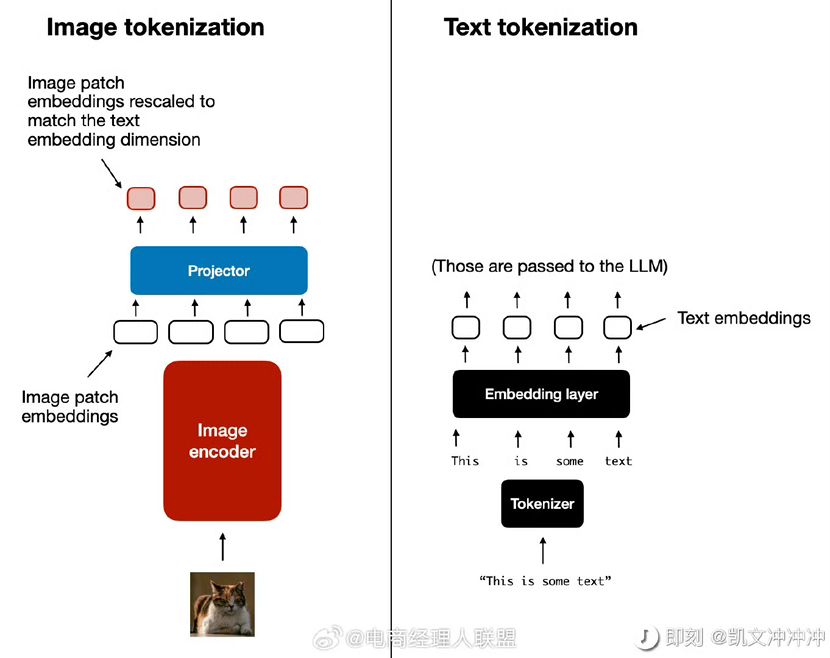
图二,这个过程就像两个人用同一种语言交流。当模型收到一个带图片的问题时,它会同时处理两种信息:一边把图片切块并理解内容,一边理解问题中的文字。然后,它会把这两种信息都转换成"机器语言"(也就是数字),这样它们就能在同一个空间里"对话",共同产生答案。
3.它的独特之处:为什么它可以工作?
图三。最新的多模态LLM有个很厉害的特点:它能处理任何大小的图片,不需要把图片压缩或裁剪到固定尺寸。这就像人类看东西一样自然,不管是看大海报还是小照片,都能看得清清楚楚。
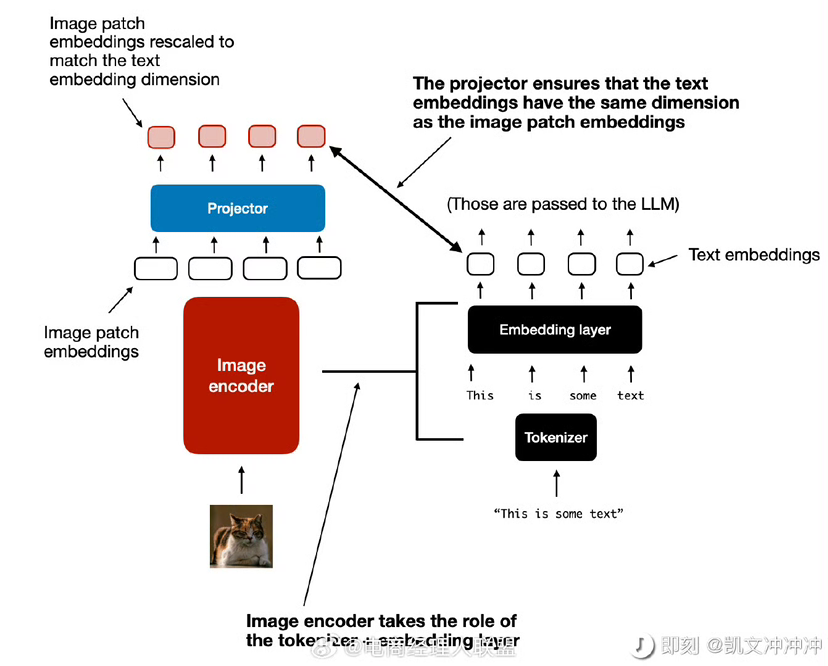
而且它能根据问题的不同,灵活地关注图片的不同部分,就像我们回答不同问题时会看向图片的不同地方一样。实际上就是文字对应着文字出来的 embedding,图片对应图片切块后出来的 embedding,这些 embedding 是在一个维度上的,可以进行对话。
但是可能还是有人不理解,当我给一张猫的图片,然后文本是 - 描述这张图片是什么的时候,模型是怎么在图片和文字进行沟通的。那还是要回到上面的第2点,图片和文字是怎么结合的。
当在训练阶段的时候,其实当我们喂给多模态模型图片时,也会给它对应的描述这张图片的文字。所以当推理阶段时,当多模态模型知道了这是一张图片,那么它会回忆起对应的训练时给它的各种文字,然后再跟文字指令进行整理合作,来产生最后的答案。
如果你单位已接入并应用DeepSeek等AI大模型或已创建智能体应用与日常工作、业务经营,欢迎加微信:89931668 告诉我们。
你们在AI上的创新应用,我们将请杭州电子商务研究院(eb.ac.cn)调研了解,或可入选为行业为典型案例,并请企通社(QitongShe.com)等媒体进行宣传报道。
DeepSeek教程与资料库
免费下载 👇🏻👇🏻👇🏻👇🏻👇🏻
PowerBy 枢纽云 搭建

































请先 登录后发表评论 ~