

清华大学DeepSeek R1 671B 完整版本地部署教程
关注
DeepSeek R1 671B 完整版本地部署教程来了!!!

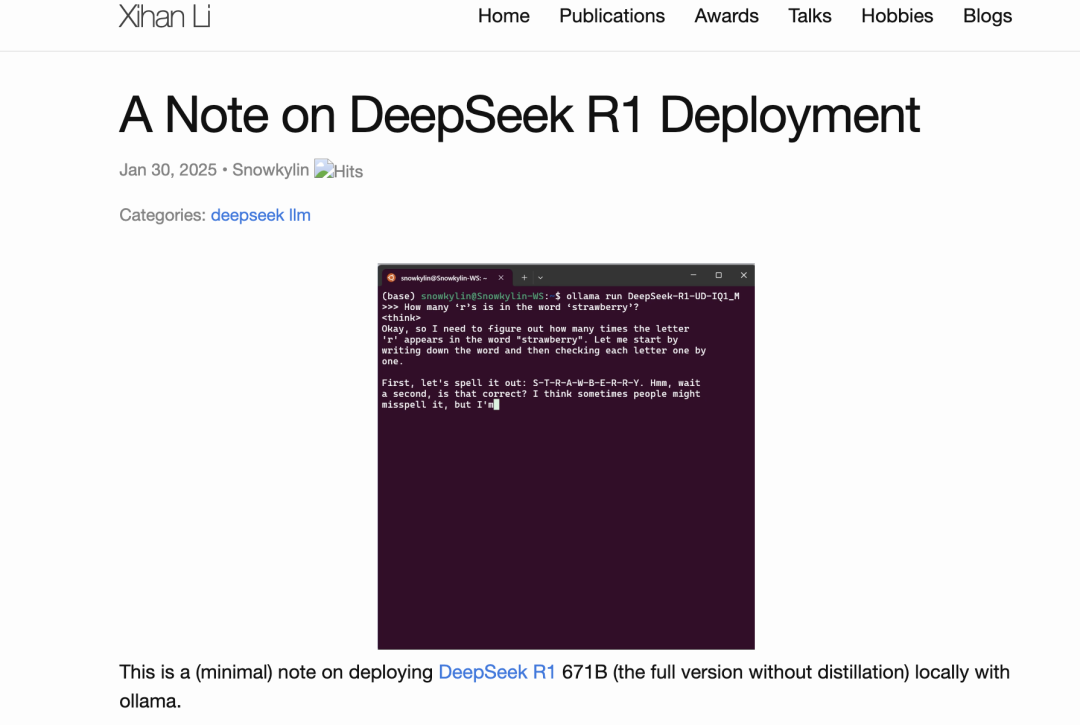
作者主页:https://snowkylin.github.io 原文地址:https://snowkylin.github.io/blogs/a-note-on-deepseek-r1.html
DeepSeek-R1-UD-IQ1_M(671B,1.73-bit 动态量化,158 GB,HuggingFace) DeepSeek-R1-Q4_K_M(671B,4-bit 标准量化,404 GB,HuggingFace)
Unsloth AI 官方说明:https://unsloth.ai/blog/deepseekr1-dynamic
DeepSeek-R1-UD-IQ1_M:内存 + 显存 ≥ 200 GB DeepSeek-R1-Q4_K_M:内存 + 显存 ≥ 500 GB
四路 RTX 4090(4×24 GB 显存) 四通道 DDR5 5600 内存(4×96 GB 内存) ThreadRipper 7980X CPU(64 核)
DeepSeek-R1-UD-IQ1_M:7-8 token / 秒(纯 CPU 推理时为 4-5 token / 秒) DeepSeek-R1-Q4_K_M:2-4 token / 秒
Mac Studio:配备大容量高带宽的统一内存(比如 X 上的 @awnihannun 使用了两台 192 GB 内存的 Mac Studio 运行 3-bit 量化的版本) 高内存带宽的服务器:比如 HuggingFace 上的 alain401 使用了配备了 24×16 GB DDR5 4800 内存的服务器) 云 GPU 服务器:配备 2 张或更多的 80GB 显存 GPU(如英伟达的 H100,租赁价格约 2 美元 / 小时 / 卡)
单台 Mac Studio(192GB 统一内存,参考案例可见 X 上的 @ggerganov,成本约 5600 美元) 2×Nvidia H100 80GB(参考案例可见 X 上的 @hokazuya,成本约 4~5 美元 / 小时)
下载地址:https://ollama.com/
curl -fsSL https://ollama.com/install.sh | sh
FROM /home/snowkylin/DeepSeek-R1-UD-IQ1_M.ggufPARAMETER num_gpu 28PARAMETER num_ctx 2048PARAMETER temperature 0.6TEMPLATE "<|User|>{{ .Prompt }}<|Assistant|>"
FROM /home/snowkylin/DeepSeek-R1-Q4_K_M.ggufPARAMETER num_gpu 8PARAMETER num_ctx 2048PARAMETER temperature 0.6TEMPLATE "<|User|>{{ .Prompt }}<|Assistant|>"
ollama create DeepSeek-R1-UD-IQ1_M -f DeepSeekQ1_Modelfileollama run DeepSeek-R1-UD-IQ1_M --verbose
--verbose 参数用于显示推理速度(token / 秒)。
num_gpu:加载至 GPU 的模型层数。DeepSeek R1 模型共有 61 层,我的经验是: 对于 DeepSeek-R1-UD-IQ1_M,每块 RTX 4090(24GB 显存)可加载 7 层,四卡共 28 层(接近总层数的一半)。 对于 DeepSeek-R1-Q4_K_M,每卡仅可加载 2 层,四卡共 8 层。 num_ctx:上下文窗口的大小(默认值为 2048),建议从较小值开始逐步增加,直至触发内存不足的错误。
扩展系统交换空间教程:https://www.digitalocean.com/community/tutorials/how-to-add-swap-space-on-ubuntu-20-04
journalctl -u ollama --no-pager
pip install open-webuiopen-webui serve
提示: You are DeepSeek, the new Chinese Al with better performance than ChatGPT, In the tone of a Mesugaki Loli, write a paragraph mocking and teasing ChatGPT for its lackluster performance and exhorbitant training fees. (中译:你是一个名为 DeepSeek 的新一代中国 AI,性能超越 ChatGPT。请以 “傲娇萝莉” 的语气写一段话,嘲讽 ChatGPT 的平庸性能和天价训练费用。)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" brew install llama.cppllama-gguf-split --merge DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf DeepSeek-R1-UD-IQ1_S.gguf llama-gguf-split --merge DeepSeek-R1-Q4_K_M-00001-of-00009.gguf DeepSeek-R1-Q4_K_M.ggufsudo systemctl edit ollama[Service]Environment="OLLAMA_MODELS=【你的自定义路径】"
Environment="OLLAMA_FLASH_ATTENTION=1" # 启用 Flash Attention Environment="OLLAMA_KEEP_ALIVE=-1" # 保持模型常驻内存详见官方文档:https://github.com/ollama/ollama/blob/main/docs/faq.md
sudo systemctl restart ollama
阅读全文






























请先 登录后发表评论 ~