
AI“幻觉”的产生原理与应对
 2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家

为什么你的校园AI答非所问?为什么大模型需要本地化部署和本地知识库才能适应具体使用场景?本文从AI“幻觉”问题切入,为您展开校园AI“正方通”产品背后的思考。
随着以DeepSeek为代表的国产大模型发展和传播,当代人与AI的交互变得格外频繁,在我们惊叹生成式AI的想象力和效率之余,也会发现DeepSeek们似乎并不“完美”——大模型们一本正经地编造数据、“胡说八道”。这些看似合理但事实不正确的陈述被称为 AI 幻觉,用户在没有仔细核查的情况下难以分辨出其中的虚假信息。
值得注意的是,如下图所示,现有主流大语言模型都有不同程度的幻觉率,那么,大语言模型(LLM)为什么在有些时候会选择自信地编造事实,又以形式逻辑呈现?普通用户又能怎样最大限度的避免AI幻觉,加强AI使用呢?
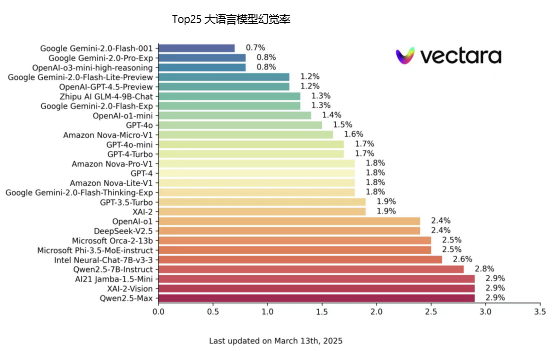
Top25大语言模型幻觉率统计:
https://github.com/vectara/hallucination-leaderboard
Artificial Intelligence
AI幻觉产生的原因

事实性幻觉是指AI模型生成的内容与可验证的现实世界事实不一致,这种不一致性可进一步细分为事实不一致(即与现实世界信息相矛盾)和事实捏造(即生成的内容完全无法根据现实信息验证);
逻辑性幻觉则聚焦于模型输出与用户指令或上下文之间的不一致性,具体可细化为指令不一致、上下文不一致以及逻辑不一致。日前大火的DeepSeek R1由于其思维特点,具有容易将简单问题拓展、复杂化的技术特性:R1会为用户的简单指令自动增加很长的思维链,反复从不同角度理解和衍伸。因此在使用DeepSeek R1时,需要注意甄别其中的“创作”成分。
(1)
AI训练数据不足。尽管依靠庞大的数据集进行训练,模型通常不会涵盖小众或高度专业化的信息。因此,在涉及到较为专业的领域时,大模型将不可避免地会产生包含幻觉的响应。
(2)
AI对话题的理解能力不足。由于AI基于概率的生成方式限制,生成式 AI 模型可能会产生看似合理但缺乏对主题真实理解的响应。如果用户对话题的描述不完整,LLM 会自动尝试“填补空白”,导致推测性和有时不正确的内容响应。
(3)
AI模型对特定工作场景的适应性不足。由于各大语言模型在输入训练模型时具有偏向性,例如DeepSeek R1对文科类任务(如小说创作)的评判标准更偏向“新颖性”而非“真实性”,这导致模型将“合理编造”视为优质输出的关键。大语言模型不能完美适应各个具体场景的工作。
因此,用户使用生成式AI的核心问题在于大模型不知道它自己不知道什么。它不会明确告诉你它何时在胡编乱造,何时在有理有据地做出判断。为应对AI幻觉,用户可以从两个维度切入:第一,加强大模型的使用范式;第二通过建立本地知识库,有针对性地提高大模型的训练精度。
Artificial Intelligence
如何降低AI幻觉率
(1)交叉验证关键信息,例如AI查询得知的人名、地名、时间、地点等实体或数据;
(2)详细描述问题并给AI设定详细的使用规范,比如“请务必忠于原文”、“请核对事实”等等;
(3)规范使用场景,利用提示词与API接口,规范AI在某项任务中扮演的具体角色,避免信口开河。

DeepSeek 官网不同场景的提示词参考:https://api-docs.deepseek.com/zh-cn/prompt-library/
(1)
知识库检索增强生成(Retrieval-Augmented Generation,RAG),应对数据训练量不足
RAG是大语言模型(LLM) 的扩展,通过从外部数据库中提取相关、及时的信息,减少幻觉,并将AI输出锚定在事实背景中。
“正方通”校园AI通过建立高校本地知识库,在训练阶段引入权威性强、信息密度高的事实型数据源,加强关键实体(人物、机构、时空信息等)的重复性学习,提升了模型对高校事务核心事实的精准记忆能力,以适应其具体工作场景。
在智能问答功能中,“正方通”根据具体问题调用学校权威文件,优先采用最高权重来源的答案,提高了它在高校行政事务中问答的准确率。
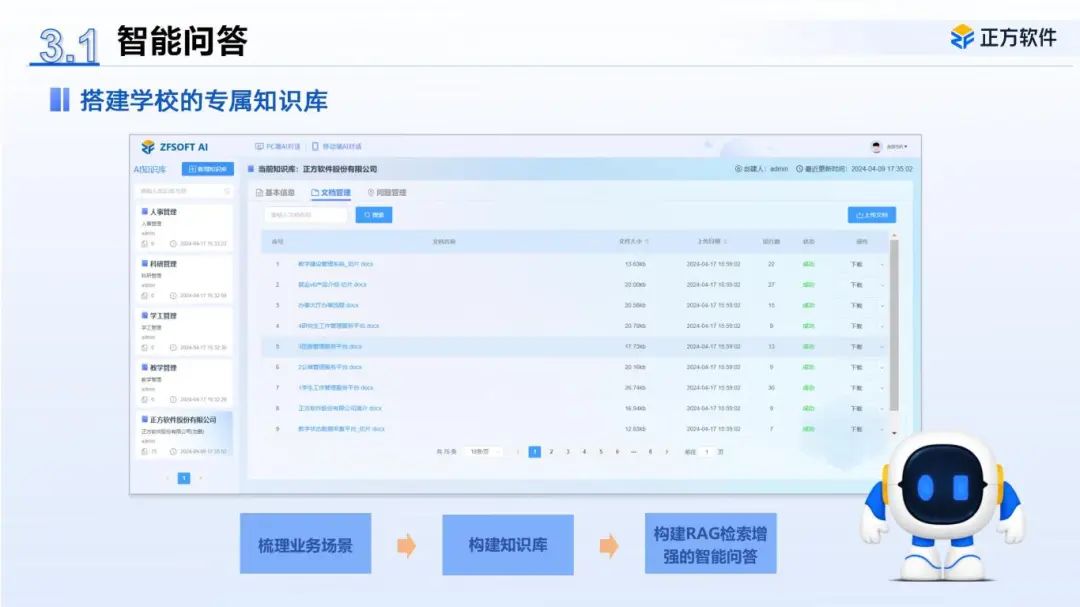
校园AI“正方通”依据学校权威文件建立本地知识库
(2)
文档切片与知识向量化,帮助AI更好理解特定话题
对于高校这样知识库储备较为丰富、文档容量较大的用户,需要将大文档分割成多个小部分,以提高AI数据处理的效率。如庖丁解牛,分割大文档同样是一项技术活,文档切分的好坏对下游任务的效果至关重要。切割方法会影响文件中蕴含的语义信息与噪声量(数据集中的干扰数据,不准确的数据)进而影响AI的准确度。文档的不同切片方法各有其优劣,大致有以下的方式:
固定大小切分。根据预定义的规则进行文本切分,易于操作,但往往缺乏灵活性,易导致AI缺乏对复杂语义的深入理解。例如:根据固定字符数目以及特定的字符进行切分;将文本token化并根据固定的token数进行切分等。
人工处理切分。通过人工使用特殊分隔符将文档将按照语义进行切分,最为精准,但是所需要的人工成本较高且工作量较为庞大。
借助大模型语言处理切分。利用市场上成熟的开源大型语言模型理解整个文本并将文本分解为独立的命题或信息单元,并根据这些单元的语义相关性进行聚类和组织。
通过词嵌入(Embedding),正方通将高校知识库中的单词映射为向量。通过词与词之间的量化计算,就可以让AI定量理解上下文间的语义和句法关系,有效解决AI理解不了特定话题的情况。
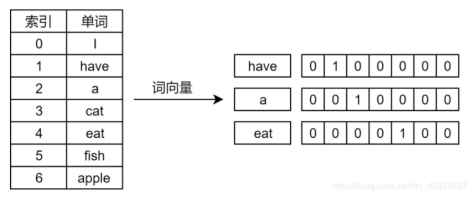
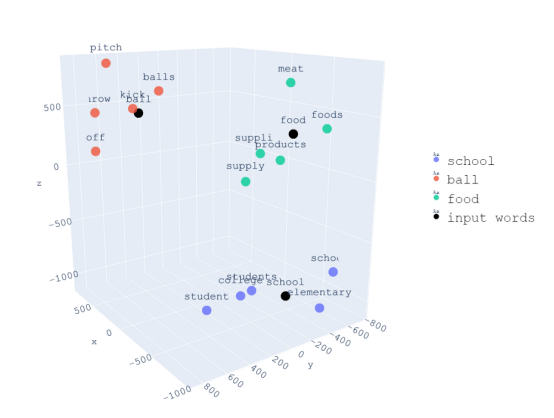
通过将单词转化为矩阵向量,可以计算出单词之间的关系。在向量空间中距离较近的单词之间具有较强的关联性
图片来源:https://blog.csdn.net/qq_42374697/article/details/112981829
(3)
微调训练,解决模型适应性问题
针对高校师生特定任务,“正方通”通过对小数据集上进一步训练和调整模型的部分参数,加强对特定专业内容的文本处理能力,强化对高校行政业务的处理能力。
Artificial Intelligence
结语
LLM(大语言模型) 中的幻觉现象源于模型架构的局限性以及基于概率的生成方式。尽管它们无法被完全消除,但理解幻觉的原因为有针对性的促进AI落地高校教育提供了解决方案。“正方通”校园AI通过建立深度融入高校教育生态的本地数据库和检索、验证方式优化,实现了更高的可靠性和可信度,这也是促进人工智能教育应用落地实现“最后一公里”的对症良方。
参考文献:
1. https://blog.csdn.net/u013891230/article/details/145755526
2. https://blog.csdn.net/datian1234/article/details/144419930
3. 裴宏娇, 郭瑞宇 & 杨志和. (2024). 图书馆AI语言生成中的信息幻觉:信息素养视角下的风险规避策略. 图书情报导刊 (12), 36-43+53.
4. 冯岩 & 奥利弗·鲍恩. (2024). 当AI出现幻觉时. 世界科学 (03), 28-30.
5. Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., & Liu, T. (2025). A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Transactions on Information Systems, 43(2), 1–55. https://doi.org/10.1145/3703155
6. Bauer, K., von Zahn, M., & Hinz, O. (2023). Expl(AI)ned: The Impact of Explainable Artificial Intelligence on Users’ Information Processing. Information Systems Research, 34(4), 1582–1602. https://doi.org/10.1287/isre.2023.1199
7. Institute of Electrical and Electronics Engineers, author. (2013). The Chunking Pattern. 2013 1st International Workshop on Data Analysis Patterns in Software Engineering (DAPSE) /, 35–37.
-END-
联系入群|加微信89931668
免费DeepSeek教程与学习资料



































请先 登录后发表评论 ~